JDK 21 新特性
1、顺序集合-Sequenced Collections
顺序集合,英文称为“Sequenced Collections”,因此也有被翻译为序列集合或者有序集合。
Java 21引入了顺序集合这种新的集合类型,这是一种具有确定出现顺序的集合。在介绍顺序集合之前,我们需要先了解什么是出现顺序(encounter order)。
出现顺序是指遍历集合时,集合中元素出现的顺序。有些集合类型具有确定的出现顺序,例如ArrayList。无论我们遍历这样的集合多少次,元素的出现顺序始终是固定的。而有些集合类型并没有确定的出现顺序,例如HashSet。如果多次遍历这样的集合,元素的出现顺序是不固定的。可以简单理解为之前我们说的ArrayList是有序的,而HashSet是无序的。
在顺序集合出现之前,Java并没有一个统一的接口来描述具有确定出现顺序的集合。虽然Set接口本身并没有确定的出现顺序,但它的子类型LinkedHashSet和SortedSet却具有。
另一个问题是,对于具有固定出现顺序的集合,Java并没有定义统一的与顺序相关的操作。与顺序集合相关的处理方法散落在Java集合类库的不同地方,使用起来并不方便。
现在,Java 21的顺序集合为我们提供了一个统一的接口来描述具有确定出现顺序的集合。这个接口定义了一些与顺序相关的操作,使得我们可以更方便地处理具有确定出现顺序的集合。
1、顺序集合相关的操作有哪些?
- 获取集合的第一个和最后一个元素
- 在集合的最前面和最后面插入或删除元素
- 按照逆序来遍历集合
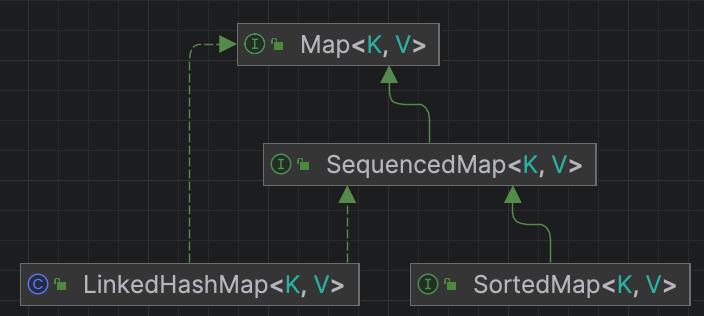
Java21的顺序集合新增了3个接口,分别是:SequencedCollection、SequencedSet和SequencedMap。新增这3个接口后,集合的继承结构发生变化,如下所示:
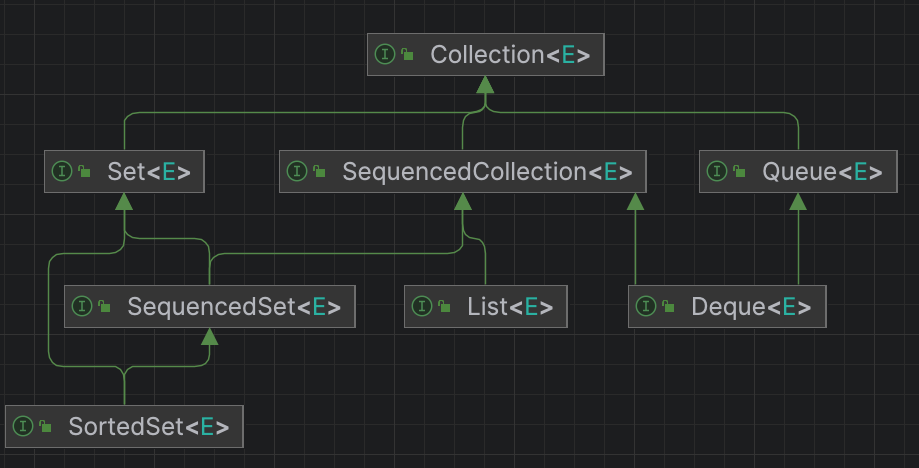
- List 继承了 SequencedCollection。
- Deque 继承了 SequencedCollection。
- LinkedHashSet 实现了 SequencedSet 接口。
- SortedSet 继承了 SequencedSet。
- SortedMap 继承了 SequencedMap。
- LinkedHashMap 实现了 SequencedMap 接口。
2、SequencedCollection接口
interface SequencedCollection<E> extends Collection<E> {
SequencedCollection<E> reversed();
void addFirst(E);
void addLast(E);
E getFirst();
E getLast();
E removeFirst();
E removeLast();
}reversed(): 返回一个逆序的 SequencedCollection 对象,也就是反转集合顺序。addFirst(): 在集合的起始添加新的元素addLast(): 在集合的结束位置添加新的元素。getFirst(): 获取集合的第一个元素getLast(): 获取集合的最后一个元素。removeFirst(): 删除集合的第一个元素,并返回该元素removeLast(): 删除集合的最后一个元素,并返回该元素。
SequencedSet 同时继承自 Set 和 SequencedCollection
interface SequencedSet<E> extends Set<E>, SequencedCollection<E> {
SequencedSet<E> reversed();
}里面就重载了一个reversed()方法,获取逆序的有序Set。
3、SequencedMap接口
interface SequencedMap<K,V> extends Map<K,V> {
SequencedMap<K,V> reversed();
SequencedSet<K> sequencedKeySet();
SequencedCollection<V> sequencedValues();
SequencedSet<Entry<K,V>> sequencedEntrySet();
V putFirst(K, V);
V putLast(K, V);
Entry<K, V> firstEntry();
Entry<K, V> lastEntry();
Entry<K, V> pollFirstEntry();
Entry<K, V> pollLastEntry();
}reversed():返回一个 entry 逆序的 SequencedMap。sequencedKeySet(): 方法返回包含 key 的 SequencedSet。sequencedValues(): 方法返回包含 value 的 SequencedCollection。sequencedEntrySet(): 方法返回包含 entry 的 SequencedSet。putFirst()和putLast(): 分别在 entry 的最前和最后位置插入键值对,并会将值返回。firstEntry()和lastEntry(): 分别获取第一个和最后一个 entry。pollFirstEntry()和pollLastEntry(): 分别删除第一个和最后一个 entry。
4、使用顺序集合的优势
- 它们提供了一种更高效的数据结构来存储和处理集合元素。
- 新的接口和方法使得对集合的操作更加灵活和方便。
- 顺序集合可以更好地满足不断变化的应用需求,提高代码的可读性和可维护性。
2、虚拟线程
1、什么是虚拟线程?
虚拟线程,英文是“Virtual Threads”,Java21中新引入虚拟线程是一种线程抽象,它提供了一种轻量级的线程实现方式,可以在用户级别进行线程调度和管理。
虚拟线程旨在改进Java中的并发编程模型。传统上,Java使用基于操作系统线程的并发模型,每个线程都需要分配一个操作系统线程来执行。而虚拟线程则提供了一种更高效、更轻量级的线程模型。这也就意味着虚拟线程可以比传统线程创建的数量更多,并且开销也更少。从而使得在自己的线程中运行单独任务或请求变得更加实用高效,能满足高吞吐量的应用程序。
2、为什么需要引入虚拟线程?
在传统的基于操作系统线程的并发模型中,创建、销毁线程以及在线程之间切换会产生较大的开销,这限制了Java应用程序在处理大规模并发时的性能和扩展性。此外,由于操作系统线程的数量有限,当应用程序需要创建大量线程时,可能会导致资源耗尽或性能下降。
为了解决这些问题,虚拟线程应运而生。它通过引入轻量级的线程模型,使Java应用程序能够创建数百万甚至数十亿个线程,而不再受操作系统线程数量的限制。这使得Java应用程序能够更好地适应大规模并发场景,并提供了更高的性能和可伸缩性。虚拟线程的出现,为Java应用程序在处理大规模并发时的性能和扩展性带来了突破性的提升。
3、虚拟线程优缺点
虚拟线程的优点主要包括:
- 更高的性能:虚拟线程能够减少线程的创建和销毁开销,同时避免受到操作系统线程数量的限制,从而提供更高的性能。
- 更好的可伸缩性:由于虚拟线程可以创建数百万甚至数十亿个线程,因此Java应用程序能够更好地适应大规模并发场景,并具有更好的可伸缩性。
- 更低的资源消耗:相比于操作系统线程,虚拟线程是轻量级的,占用的内存和CPU资源更少。
然而,虚拟线程也存在一些潜在的缺点:
- 学习成本较高:使用虚拟线程需要对并发编程模型有一定的理解,并且需要适应新的API和开发范式。
- 可能引入新的问题:由于虚拟线程是一个相对较新的功能,可能会存在一些未知的问题或者不稳定性。
4、如何创建和使用虚拟线程
1、使用静态构建器方法
Thread.startVirtualThread方法将可运行Runnable对象作为参数来创建,并立即启动运行虚拟线程
Runnable runnable = () -> {
System.out.println("Hello, https://blog.xueqimiao.com");
};
// 使用静态构建器方法
Thread virtualThread = Thread.startVirtualThread(runnable);也可以使用Thread.ofVirtual()来创建,这里还可以设置一些属性,比如:线程名称
Runnable runnable = () -> {
System.out.println("Hello, https://blog.xueqimiao.com");
};
// 使用静态构建器方法
Thread virtualThread = Thread.startVirtualThread(runnable);
Thread.ofVirtual()
.name("xx-virtual-thread")
.start(runnable);2、与ExecutorService结合使用
从JDK5开始,就推荐开发人员使用ExecutorServices而不是直接使用Thread类了。现在,Java 21中引入了使用虚拟线程,所以也有了新的ExecutorService来适配,一起看下下面的代码:
Runnable runnable = () -> {
System.out.println("Hello, https://blog.xueqimiao.com");
};
try (ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 0; i < 10; i++) {
executorService.submit(runnable);
}
}上述代码在try代码块中创建了一个ExecutorService,用来为每个提交的任务创建虚拟线程来运行处理。
5、虚拟线程的使用注意事项
- 虽然虚拟线程可以创建大量线程,但过多的线程仍可能导致性能下降或资源耗尽。因此,在设计应用程序时,仍需合理控制并发度。
- 使用虚拟线程时,需要遵循良好的并发编程实践,如避免共享可变状态、使用适当的同步机制等,以确保线程安全性和正确性。
- 在迁移现有代码到使用虚拟线程时,需要进行一定的重构和调整,以适应新的API和开发范式。
3、switch模式匹配
1、单匹配,不用再写break,支持返回值
String day = "MONDAY";
String i = switch (day) {
case "MONDAY" -> "星期1";
case "TUESDAY" -> "星期2";
case "WEDNESDAY" -> "星期3";
case "THURSDAY" -> "星期4";
case "FRIDAY" -> "星期5";
case "SATURDAY" -> "星期6";
case "SUNDAY" -> "星期7";
default -> "未知";
};
System.out.println(i);2、执行多行代码,可使用yield返回
String day = "MONDAY";
String i = switch (day) {
case "MONDAY" -> {
System.out.println("又要上班了...");
yield "星期1";
}
case "TUESDAY" -> "星期2";
case "WEDNESDAY" -> "星期3";
case "THURSDAY" -> "星期4";
case "FRIDAY" -> "星期5";
case "SATURDAY" -> "星期6";
case "SUNDAY" -> "星期7";
default -> "未知";
};
System.out.println(i);3、多匹配,直接逗号分割
String day = "SUNDAY";
String i = switch (day) {
case "MONDAY" -> "星期 1";
case "TUESDAY" -> "星期2";
case "WEDNESDAY" -> "星期3";
case "THURSDAY" -> "星期4";
case "FRIDAY" -> "星期5";
case "SATURDAY", "SUNDAY" -> "周末";
default -> "未知";
};
System.out.println(i);4、匹配增强
比如java21版本之前,我们根据不同类型数据格式化输出:
static String formatter(Object obj) {
String formatted = "unknown";
if (obj instanceof Integer i) {
formatted = String.format("int %d", i);
} else if (obj instanceof Long l) {
formatted = String.format("long %d", l);
} else if (obj instanceof Double d) {
formatted = String.format("double %f", d);
} else if (obj instanceof String s) {
formatted = String.format("String %s", s);
}
return formatted;
}以上代码得益于instanceof表达式看上去还不错,但是并不完美,我们可以考虑扩展switch语句和表达式,使其适用于任何类型,并允许case带有模式的标签而不仅仅是常量。这样的改进将使我们的代码更加清晰、可靠和灵活,如下:
static String formatterPatternSwitch(Object obj) {
return switch (obj) {
case Integer i -> String.format("int %d", i);
case Long l -> String.format("long %d", l);
case Double d -> String.format("double %f", d);
case String s -> String.format("String %s", s);
default -> obj.toString();
};
}5、对于null处理
Java21以前, 如果选择器表达式的计算结果为null,则switch语句和表达式会抛出空指针异常,但是现在可以直接对null进行判断,类似如下:
String str = null;
switch (str) {
case null -> System.out.println("Oops");
case "Foo", "Bar" -> System.out.println("Great");
default -> System.out.println("Ok");
}4、分代ZGC
在Java 21中,引入了一项新的垃圾收集器特性——分代ZGC(Generational ZGC)。分代ZGC是一种更为高效的垃圾收集器,它位于在 hotspot/gc 包中,它通过扩展Z垃圾回收器(ZGC)来维护年轻对象和年老对象的独立生成,对内存区域进行分代管理,以及采用更为精细的垃圾收集策略,使ZGC能够更频繁地收集年轻对象(这些对象往往英年早逝),从而提高了Java应用程序的性能和响应速度
1、什么是分代ZGC
Generational ZGC(Z Garbage Collector)是一种用于Java虚拟机(JVM)的垃圾回收器。它是OpenJDK项目中的一个特性,旨在提供低延迟和高吞吐量的垃圾回收解决方案。
2、分代ZGC设计目标
- 使用新一代 ZGC 运行的应用程序应享有
- 降低分配停滞的风险、
- 降低堆内存开销
- 降低垃圾回收 CPU 开销。
- 与非分代 ZGC 相比,这些优势不应导致吞吐量的显著降低。应保留非分代 ZGC 的基本特性:
- 暂停时间不应超过 1 毫秒
- 支持从几百兆字节到几千兆字节的堆大小
- 以及应尽量减少手动配置
- 以最后一点为例,应无需手动配置
- 代的大小
- 垃圾回收器使用的线程数
- 或对象应在年轻代中停留多长时间
最后,与非分代ZGC相比,分代ZGC在大多数使用情况下都是更好的解决方案。我们最终应该能用分代 ZGC取代非分代 ZGC,以降低长期维护成本。
3、为什么需要分代ZGC?
传统的垃圾回收器在处理大型堆内存时可能会导致长时间的停顿,这对于需要快速响应和低延迟的应用程序来说是不可接受的。Generational ZGC的目标是减少这些停顿时间,并且能够处理非常大的堆内存。
4、分代ZGC实现原理
Generational ZGC基于分代垃圾回收的概念,将堆内存划分为多个代。其中包括Young Generation(年轻代)和Old Generation(老年代)。具体的实现原理如下:
1、年轻代(Young Generation)
- 年轻代使用了Region的概念,将整个年轻代划分为多个大小相等的区域。
- 每个区域都有一个指针指向下一个可用的区域,形成一个链表结构。
- 当对象被创建时,它们首先被分配到年轻代的某个区域中。
- 当一个区域被填满时,会触发一次年轻代垃圾回收(Minor GC)。
- Minor GC使用了并行和压缩算法来回收不再使用的对象。
2、老年代(Old Generation)
- 老年代是存放生命周期较长的对象的区域。
- 当一个对象在年轻代经历了多次垃圾回收后仍然存活,它将被晋升到老年代。
- 当老年代空间不足时,会触发一次老年代垃圾回收(Major GC)。
- Major GC使用了并发标记和并行清理算法来回收不再使用的对象。
3、并发处理
Generational ZGC采用了并发处理的方式来减少停顿时间。具体包括:
- 年轻代垃圾回收过程中,应用程序可以继续执行。
- 在老年代垃圾回收过程中,应用程序也可以继续执行,只有在最后的清理阶段才会产生短暂的停顿。
5、分代ZGC的优点
- 低延迟:Generational ZGC通过并发处理和分代回收的策略,实现了非常低的停顿时间,适合对响应时间要求高的应用场景。
- 高吞吐量:Generational ZGC在尽可能减少停顿时间的同时,也能保持较高的垃圾回收吞吐量。
- 大堆支持:Generational ZGC可以处理非常大的堆内存,适用于需要大内存容量的应用程序。
6、分代ZGC的缺点
- 性能开销:由于并发处理和分代回收的策略,Generational ZGC会带来一定的性能开销。这主要体现在CPU和内存的使用上。
- 配置复杂:Generational ZGC有一些与性能相关的配置参数,需要根据具体场景进行调整,对于不熟悉的用户来说可能比较复杂。
7、如何启用分代 ZGC?
为确保顺利接替,将同时提供分代 ZGC 和非分代 ZGC。命令行选项 -XX:+UseZGC 将选择非分代 ZGC;要选择分代 ZGC,请添加 -XX:+ZGenerational 选项:
java -XX:+UseZGC -Xmx8g -XX:+ZGenerational在上面的代码中,我们通过添加启动参数 -XX:+UseZGC -Xmx8g 来启用分代ZGC,并将堆内存设置为 8GB。在未来的版本中,我们可以将分代 ZGC 设为默认值,届时 -XX:-ZGenerational 将选择非分代 ZGC。在更高的版本中,将会删除非分代 ZGC,到时候ZGenerational 选项将过时。
5、准备禁止动态加载代理
1、 什么是动态加载代理禁用准备?
动态加载代理禁用准备(Prepare to Disallow the Dynamic Loading of Agents)是一个Java增强提案,其目标是在JVM中禁止动态加载代理。代理是一种能够修改或监视应用程序行为的机制,它可以通过字节码注入来实现。
2、为什么需要动态加载代理禁用准备?
动态加载代理允许开发人员在运行时修改和监视Java应用程序的行为。虽然这对于调试和性能分析等方面非常有用,但也存在潜在的安全风险。恶意代码可能会利用动态加载代理的功能来执行恶意操作,例如窃取敏感信息、篡改数据等。
因此,为了加强Java应用程序的安全性,限制动态加载代理的使用是很有必要的。
3、动态加载代理禁用准备的实现原理
动态加载代理禁用准备的实现涉及到以下几个方面:
1、修改ClassLoader
该提案建议修改Java虚拟机的类加载器,以阻止动态加载代理。具体而言,将在java.lang.ClassLoader 类中添加一个新的方法boolean disallowDynamicAgentLoading(),默认返回false。当该方法被调用时,将返回true,表示禁止动态加载代理。
2、修改Instrumentation API
为了支持ClassLoader的修改,还需要对Java虚拟机的Instrumentation API进行相应的更改。具体而言,将在java.lang.instrument.Instrumentation 接口中添加一个新的方法boolean isDynamicAgentLoadingAllowed(),默认返回true。当该方法返回false时,表示禁止动态加载代理。
3、更新安全管理器
此外,还建议更新Java虚拟机的安全管理器(SecurityManager),以允许检查是否允许动态加载代理。这样可以通过安全策略来控制哪些代码可以使用动态加载代理功能。
4、动态加载代理禁用准备的优点
- 提高Java应用程序的安全性:禁止动态加载代理可以防止恶意代码利用其功能执行潜在的危险操作。
- 简化安全配置:通过更新安全管理器和类加载器,可以更方便地控制动态加载代理的使用权限,简化安全配置过程。
5、动态加载代理禁用准备的缺点
- 可能影响现有代码:如果现有代码依赖于动态加载代理的功能,那么禁用它可能会导致这些代码无法正常工作。因此,在应用该增强提案之前,需要仔细评估现有代码的依赖关系。
6、StringBuilder和StringBuffer新增repeat方法
Java21针对StringBuilder和StringBuffer这两个类都新增了一个名为repeat的方法,我们一起看下该方法的源码:
/**
* @throws IllegalArgumentException {@inheritDoc}
*
* @since 21
*/
@Override
public StringBuilder repeat(int codePoint, int count) {
super.repeat(codePoint, count);
return this;
}
/**
* @throws IllegalArgumentException {@inheritDoc}
*
* @since 21
*/
@Override
public StringBuilder repeat(CharSequence cs, int count) {
super.repeat(cs, count);
return this;
}看样子是继承子父类,有两个重载方法,尝试用一下:
StringBuilder sb = new StringBuilder().repeat("@", 5);
System.out.println(sb);运行输出:
@@@@@这里我们用的是第二个重载方法,第一个repeat方法第一个参数是int型codePoint,指得应该是UniCode字符集中的codePoint,所以这个方法的repeat是针对UniCode字符的。
7、密钥封装机制 API
密钥封装机制 API 介绍一种用于密钥封装机制(Key Encapsulation Mechanism,简称KEM)的API,这是一种通过公共加密来保护对称密钥的加密技术。
该提案的一个目标是使应用程序能够使用KEM算法,如RSA密钥封装机制(RSA-KEM)、椭圆曲线集成加密方案(ECIES),以及美国国家标准与技术研究所(NIST)后量子密码学标准化过程的候选算法。
另一个目标是使KEM能够在更高级别的协议(如传输层安全性(TLS))和加密方案(如混合公钥加密(HPKE))中使用。
此外,安全提供商将能够在Java代码或本机代码中实现KEM算法,并包括在RFC 9180中定义的Diffie-Hellman KEM(DHKEM)的实现。
值得注意的是,最初针对 JDK 21 的JEP 404, Generational Shenandoah(实验性)已从 JDK 21 的最终功能集中正式删除。这是由于“审查过程中发现的风险以及缺乏时间”可以执行如此大的代码贡献所需的彻底审查。” Shenandoah 团队决定“尽其所能提供最好的 Generational Shenandoah”,并将寻求以 JDK 22 为目标。
我们研究了其中一些新功能,并包括它们在四个主要 Java 项目( Amber、Loom、Panama和Valhalla )支持下的位置,这些项目旨在孵化一系列组件,以便通过精心策划的合并最终包含在 JDK 中。