Redis面试题
1、Redis是单线程还是多线程
这个问题不能简单地用“是”或“否”来回答。Redis的“单线程”标签主要指的是其网络请求处理和命令执行模型,但随着版本的演进,Redis逐步引入了多线程机制来处理特定任务。下面按版本进行说明:
🔹 Redis 2.6(2012年10月)
- 引入了Lua脚本(EVAL命令),增强了原子性操作。
- 处理命令仍是典型的单线程。
🔹 Redis 3.x(2015年4月)
- 引入了Redis Cluster,实现分布式集群。
- 每个节点仍然是单线程处理客户端命令,多个节点并行带来了“逻辑多线程”。
🔹 Redis 4.x(2017年7月)
- 开始引入异步删除键值的多线程机制(如UNLINK命令),解决大键阻塞问题。
- 虽然命令处理仍是单线程,但开始使用多线程处理后台任务(如key删除、AOF重写等)。
- 从这个版本起,Redis 不再是严格意义上的单线程。
🔹 Redis 5.x(2018年10月)
- 进行了内部代码的结构性重构,为多线程打下更坚实的基础。
- 添加了Streams数据结构,但处理模式仍是“主线程处理命令 + 后台线程做辅助”。
🔹 Redis 6.x(2020年5月)
- 是关键转折点。引入了多线程IO机制:
- 主线程仍处理命令解析与执行,
- 但网络IO读写(accept、read、write)可以由多个线程并行完成(需手动开启)。
- 实现了**“半多线程模型”**,大大提升了多核CPU下的性能。
✅ 总结
- Redis 核心命令执行仍然由主线程串行处理,这是为了保持操作的原子性和简单性。
- 但从 4.x 开始 Redis 就引入了多线程辅助功能,6.x 更是实质性引入了IO多线程,提高并发处理能力。
因此,Redis不是纯粹的单线程系统,而是逐步引入多线程特性的高性能键值数据库。
2、Redis3.x单线程时代但性能依旧很快的主要原因
基于内存操作:Redis 的所有数据都存在内存中,因此所有的运算都是内存级别的,所以他的性能比较高; 数据结构简单:Redis 的数据结构是专门设计的,而这些简单的数据结构的查找和操作的时间大部分复杂度都是 O(1),因此性能比较高; 多路复用和非阻塞 I/O:Redis使用 I/O多路复用功能来监听多个 socket连接客户端,这样就可以使用一个线程连接来处理多个请求,减少线程切换带来的开销,同时也避免了 I/O 阻塞操作 避免上下文切换:因为是单线程模型,因此就避免了不必要的上下文切换和多线程竞争,这就省去了多线程切换带来的时间和性能上的消耗,而且单线程不会导致死锁问题的发生 作者原话大致解析:Redis 是基于内存操作的,因此他的瓶颈可能是机器的内存或者网络带宽而并非 CPU,既然 CPU 不是瓶颈,那么自然就采用单线程的解决方案了,况且使用多线程比较麻烦
3、为什么逐渐加入了多线程特性?
正常情况下使用 del 指令可以很快的删除数据,而当被删除的 key 是一个非常大的对象时,例如时包含了成千上万个元素的 hash 集合时,那么 del 指令就会造成 Redis 主线程卡顿。 这就是redis3.x单线程时代最经典的故障,大key删除的头疼问题, 由于redis是单线程的,del bigKey ..... 等待很久这个线程才会释放,类似加了一个synchronized锁,你可以想象高并发下,程序堵成什么样子?
4、Redis6.0默认是否开启了多线程?
Redis将所有数据放在内存中,内存的响应时长大约为100纳秒,对于小数据包,Redis服务器可以处理8W到10W的QPS,这也是Redis处理的极限了,对于80%的公司来说,单线程的Redis已经足够使用了。
在Redis6.0中,多线程机制默认是关闭的,如果需要使用多线程功能,需要在redis.conf中完成两个设置 1.设置io-thread-do-reads配置项为yes,表示启动多线程 2.设置线程个数。关于线程数的设置,官方的建议是如果为 4 核的 CPU,建议线程数设置为 2 或 3,如果为 8 核 CPU 建议线程数设置为 6,线程数一定要小于机器核数,线程数并不是越大越好。
5、Redis的八种数据类型,分别是什么应用场景
string hash list set zset bitmap hyperloglog geo
1、string
文章浏览量,只要点击了,直接可以使用incr key 命令增加一个数字1,完成记录数字
2、hash
购物车
新增商品 → hset shopcar:uid1024 334488 1 新增商品 → hset shopcar:uid1024 334477 1 增加商品数量 → hincrby shopcar:uid1024 334477 1 商品总数 → hlen shopcar:uid1024 全部选择 → hgetall shopcar:uid102
3、list
微信公众号订阅的消息
用户ID,立即参与按钮 sadd key 用户ID 显示已经有多少人参与了,上图23208人参加 SCARD key 抽奖(从set中任意选取N个中奖人) SRANDMEMBER key 2 随机抽奖2个人,元素不删除 SPOP key 3 随机抽奖3个人,元素会删除 微信朋友圈: 新增点赞 sadd pub:msgID 点赞用户ID1 点赞用户ID2 取消点赞 srem pub:msgID 点赞用户ID 展现所有点赞过的用户 SMEMBERS pub:msgID 点赞用户数统计,就是常见的点赞红色数字 scard pub:msgID 判断某个朋友是否对楼主点赞过 SISMEMBER pub:msgID 用户ID 微博好友关注社交 - 共同关注的人 关注了他们两个,只要他们发布了新文章,就会安装进我的List lpush likearticle:id 11 22 查看自己的号订阅的全部文章 lrange likearticle:id 0 9
4、set
抽奖小程序
用户ID,立即参与按钮 sadd key 用户ID 显示已经有多少人参与了,上图23208人参加 SCARD key 抽奖(从set中任意选取N个中奖人) SRANDMEMBER key 2 随机抽奖2个人,元素不删除 SPOP key 3 随机抽奖3个人,元素会删除
5、zset
根据商品销售对商品进行排序显示
思路:定义商品销售排行榜(sorted set集合),key为goods:sellsort,分数为商品销售数量。
商品编号1001的销量是9,商品编号1002的销量是15 zadd goods:sellsort 9 1001 15 1002
有一个客户又买了2件商品1001,商品编号1001销量加2 zincrby goods:sellsort 2 1001
求商品销量前10名 ZRANGE goods:sellsort 0 10 withscores
抖音热搜
点击视频
ZINCRBY hotvcr:20200919 1 八佰
ZINCRBY hotvcr:20200919 15 八佰 2 花木兰
展示当日排行前10条
ZREVRANGE hotvcr:20200919 0 9 withscores6、bitmap
京东签到领取京豆
签到日历仅展示当月签到数据
签到日历需展示最近连续签到天数
假设当前日期是20210618,且20210616未签到
若20210617已签到且0618未签到,则连续签到天数为1
若20210617已签到且0618已签到,则连续签到天数为27、hyperloglog
天猫网站首页亿级UV的Redis统计方案 统计日活
8、geo
美团地图位置附近的酒店推送
6、布隆过滤器怎么用?
介绍
- 由一个初值都为零的bit数组和多个哈希函数构成,用来快速判断某个数据是否存在
- 本质就是判断具体数据存不存在一个大的集合中
- 布隆过滤器是一种类似set的数据结构,只是统计结果不太准确
特点
- 高效地插入和查询,占用空间少,返回的结果是不确定性的。
- 一个元素如果判断结果为存在的时候元素不一定存在,但是判断结果为不存在的时候则一定不存在。
- 布隆过滤器可以添加元素,但是不能删除元素。因为删掉元素会导致误判率增加。
- 误判只会发生在过滤器没有添加过的元素,对于添加过的元素不会发生误判。
备注:
有,是可能有
无,是肯定无
可以保证的是,如果布隆过滤器判断一个元素不在一个集合中,那这个元素一定不会在集合中
使用场景
- 解决缓存穿透的问题
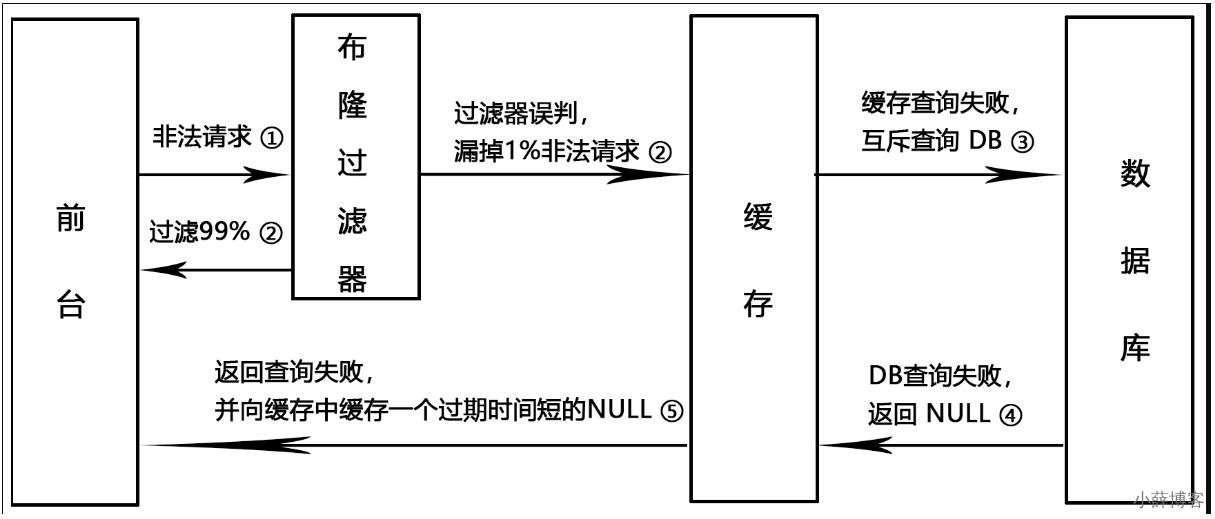
缓存穿透是什么
一般情况下,先查询缓存redis是否有该条数据,缓存中没有时,再查询数据库。
当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透。
缓存透带来的问题是,当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库。
可以使用布隆过滤器解决缓存穿透的问题
把已存在数据的key存在布隆过滤器中,相当于redis前面挡着一个布隆过滤器。
当有新的请求时,先到布隆过滤器中查询是否存在:
如果布隆过滤器中不存在该条数据则直接返回;
如果布隆过滤器中已存在,才去查询缓存redis,如果redis里没查询到则穿透到Mysql数据库
- 黑名单校验
发现存在黑名单中的,就执行特定操作。比如:识别垃圾邮件,只要是邮箱在黑名单中的邮件,就识别为垃圾邮件。
假设黑名单的数量是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决方案。
把所有黑名单都放在布隆过滤器中,在收到邮件时,判断邮件地址是否在布隆过滤器中即可。
原理
- Java中传统hash
哈希函数的概念是:将任意大小的输入数据转换成特定大小的输出数据的函数,转换后的数据称为哈希值或哈希编码,也叫散列值

如果两个散列值是不相同的(根据同一函数)那么这两个散列值的原始输入也是不相同的。
这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。
散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同,
这种情况称为“散列碰撞(collision)”。
用 hash表存储大数据量时,空间效率还是很低,当只有一个 hash 函数时,还很容易发生哈希碰撞。
- Java中hash冲突java案例
public class HashCodeConflictDemo
{
public static void main(String[] args)
{
Set<Integer> hashCodeSet = new HashSet<>();
for (int i = 0; i <200000; i++) {
int hashCode = new Object().hashCode();
if(hashCodeSet.contains(hashCode)) {
System.out.println("出现了重复的hashcode: "+hashCode+"\t 运行到"+i);
break;
}
hashCodeSet.add(hashCode);
}
System.out.println("Aa".hashCode());
System.out.println("BB".hashCode());
System.out.println("柳柴".hashCode());
System.out.println("柴柕".hashCode());
}
}1、布隆过滤器实现原理和数据结构
布隆过滤器原理
布隆过滤器(Bloom Filter) 是一种专门用来解决去重问题的高级数据结构。
实质就是一个大型位数组和几个不同的无偏hash函数(无偏表示分布均匀)。由一个初值都为零的bit数组和多个个哈希函数构成,用来快速判断某个数据是否存在。但是跟 HyperLogLog 一样,它也一样有那么一点点不精确,也存在一定的误判概率
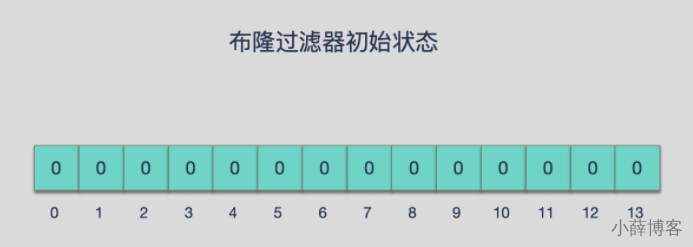
添加key时
使用多个hash函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,
每个hash函数都会得到一个不同的位置,将这几个位置都置1就完成了add操作。
查询key时
只要有其中一位是零就表示这个key不存在,但如果都是1,则不一定存在对应的key。
结论:
有,是可能有
无,是肯定无
当有变量被加入集合时,通过N个映射函数将这个变量映射成位图中的N个点,
把它们置为 1(假定有两个变量都通过 3 个映射函数)。
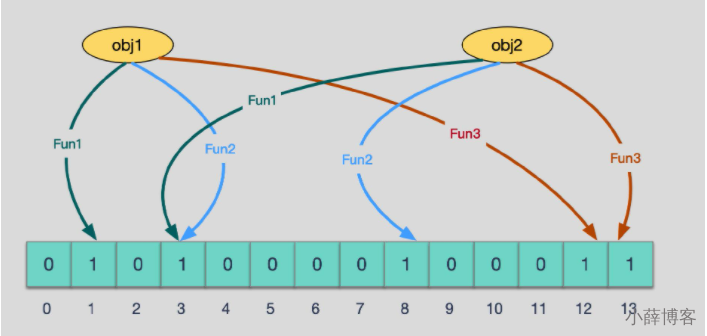
查询某个变量的时候我们只要看看这些点是不是都是 1, 就可以大概率知道集合中有没有它了
如果这些点,有任何一个为零则被查询变量一定不在,
如果都是 1,则被查询变量很可能存在,
为什么说是可能存在,而不是一定存在呢?那是因为映射函数本身就是散列函数,散列函数是会有碰撞的。

2、3步骤


向布隆过滤器查询某个key是否存在时,先把这个 key 通过相同的多个 hash 函数进行运算,查看对应的位置是否都为 1,
只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在;
如果这几个位置全都是 1,那么说明极有可能存在;
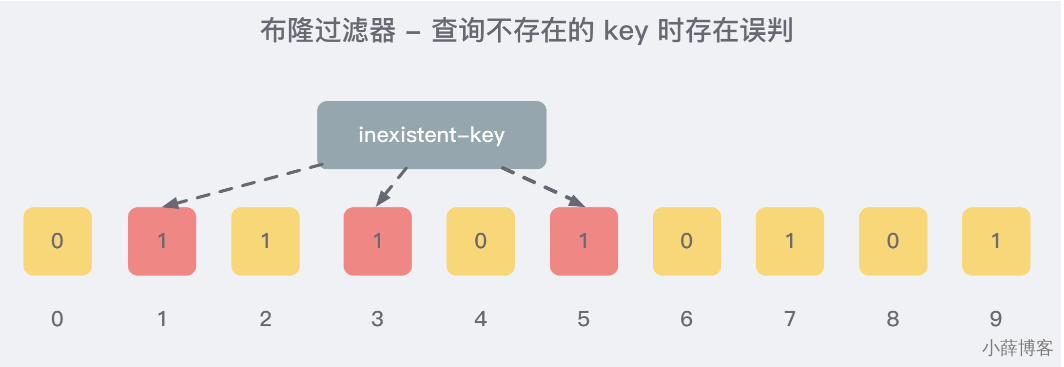
因为这些位置的 1 可能是因为其他的 key 存在导致的,也就是前面说过的hash冲突。。。。。
就比如我们在 add 了字符串wmyskxz数据之后,很明显下面1/3/5 这几个位置的 1 是因为第一次添加的 wmyskxz 而导致的;
此时我们查询一个没添加过的不存在的字符串inexistent-key,它有可能计算后坑位也是1/3/5 ,这就是误判了......


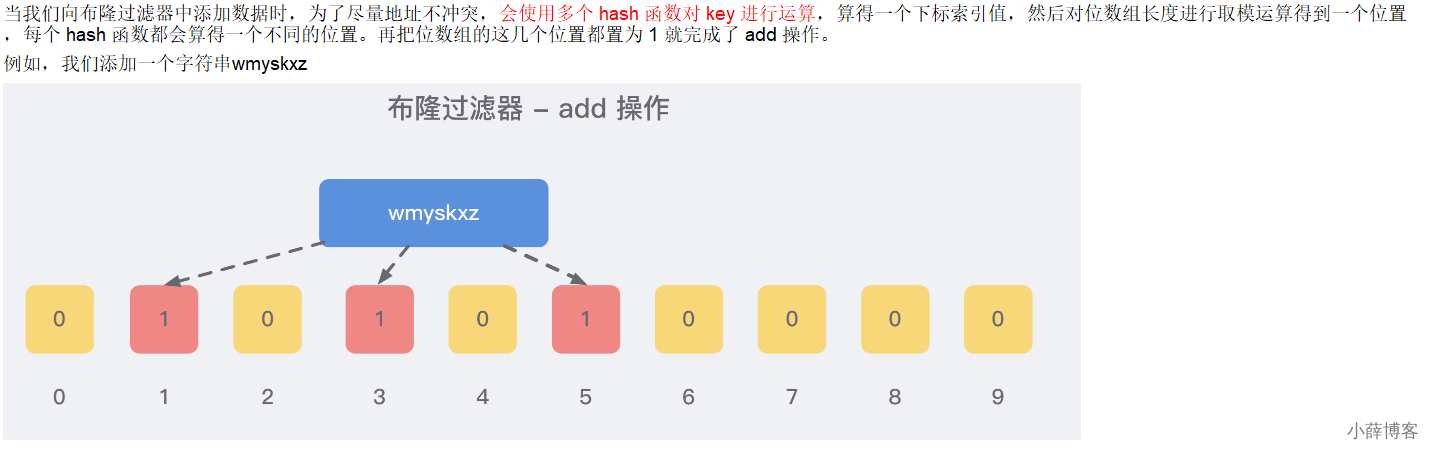
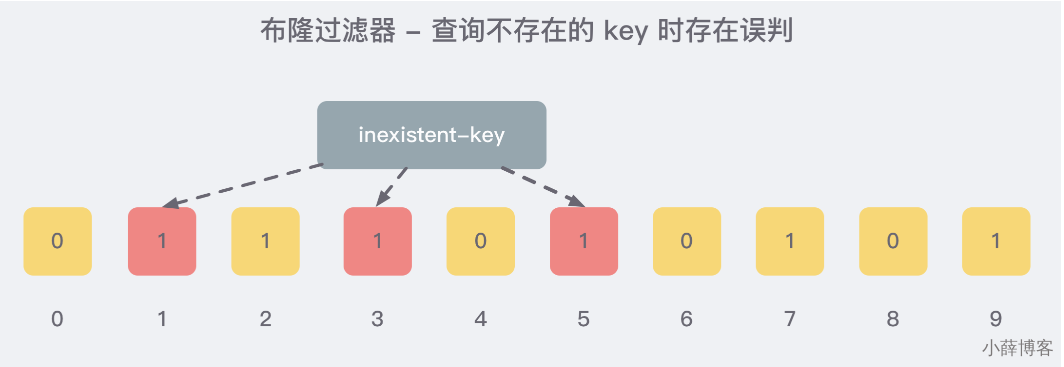
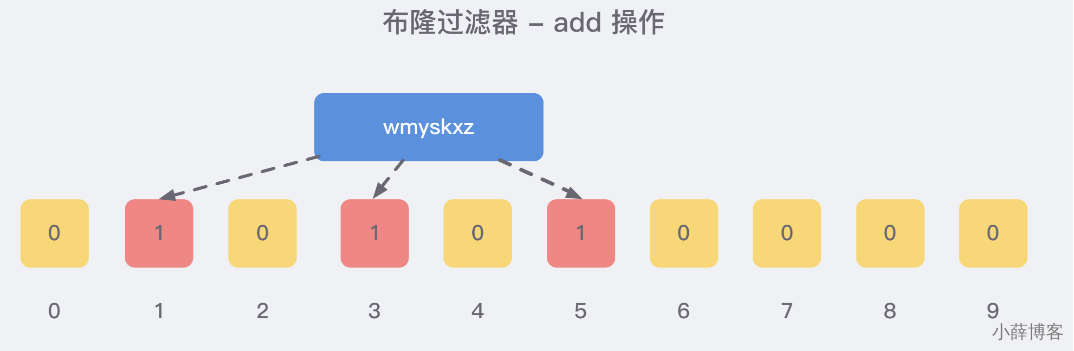
3、布隆过滤器误判率,为什么不要删除
布隆过滤器的误判是指多个输入经过哈希之后在相同的bit位置1了,这样就无法判断究竟是哪个输入产生的,
因此误判的根源在于相同的 bit 位被多次映射且置 1。
这种情况也造成了布隆过滤器的删除问题,因为布隆过滤器的每一个 bit 并不是独占的,很有可能多个元素共享了某一位。
如果我们直接删除这一位的话,会影响其他的元素
特性
一个元素判断结果为没有时则一定没有,
如果判断结果为存在的时候元素不一定存在。
布隆过滤器可以添加元素,但是不能删除元素。因为删掉元素会导致误判率增加。
4、总结
是否存在
- 有,是很可能有
- 无,是肯定无
- 可以保证的是,如果布隆过滤器判断一个元素不在一个集合中,那这个元素一定不会在集合中
使用时最好不要让实际元素数量远大于初始化数量
当实际元素数量超过初始化数量时,应该对布隆过滤器进行重建,重新分配一个 size 更大的过滤器,再将所有的历史元素批量 add 进行
6、优缺点
优点:
- 高效地插入和查询,占用空间少
缺点
- 不能删除元素。因为删掉元素会导致误判率增加,因为hash冲突同一个位置可能存的东西是多个共有的,你删除一个元素的同时可能也把其它的删除了。
- 存在误判不同的数据可能出来相同的hash值
7、布谷鸟过滤器
为了解决布隆过滤器不能删除元素的问题,布谷鸟过滤器横空出世。论文《Cuckoo Filter:Better Than Bloom》
作者将布谷鸟过滤器和布隆过滤器进行了深入的对比。相比布谷鸟过滤器而言布隆过滤器有以下不足:
查询性能弱、空间利用效率低、不支持反向操作(删除)以及不支持计数
7、Redis除了拿来做缓存,你还见过基于Redis的什么用法?
分布式锁
8、Redis 做分布式锁的时候有需要注意的问题?
1、独占性
OnlyOne,任何时刻只能有且仅有一个线程持有
2、高可用
若redis集群环境下,不能因为某一个节点挂了而出现获取锁和释放锁失败的情况
3、防死锁
杜绝死锁,必须有超时控制机制或者撤销操作,有个兜底终止跳出方案
4、不乱抢
防止张冠李戴,不能私下unlock别人的锁,只能自己加锁自己释放。
5、重入性
同一个节点的同一个线程如果获得锁之后,它也可以再次获取这个锁。
9、那你简单的介绍一下 Redlock 吧?你简历上写redisson,你谈谈
1、使用场景
多个服务间保证同一时刻同一时间段内同一用户只能有一个请求(防止关键业务出现并发攻击)
Redis分布式锁比较正确的姿势是采用redisson这个客户端工具
2、RedLock Java的实现 Redisson
英文:https://redis.io/topics/distlock
中文:http://redis.cn/topics/distlock.html
Redisson是java的redis客户端之一,提供了一些api方便操作redis
redisson之官网:https://redisson.org/
redisson之Github:https://github.com/redisson/redisson/wiki/1.-Overview
redisson之解决分布式锁:https://github.com/redisson/redisson/wiki/8.-Distributed-locks-and-synchronizers
3、单机案例
1、三个重要元素
加锁
- 加锁实际上就是在redis中,给Key键设置一个值,为避免死锁,并给定一个过期时间
解锁
- 将Key键删除。但也不能乱删,不能说客户端1的请求将客户端2的锁给删除掉,只能自己删除自己的锁
- Lua
为了保证解锁操作的原子性,我们用LUA脚本完成这一操作。先判断当前锁的字符串是否与传入的值相等,是的话就删除Key,解锁成功。
if redis.call('get',KEYS[1]) == ARGV[1] then
return redis.call('del',KEYS[1])
else
return 0
end超时
- 锁key要注意过期时间,不能长期占用
加锁关键逻辑:
public static boolean tryLock(String key, String uniqueId, int seconds) {
return "OK".equals(jedis.set(key, uniqueId, "NX", "EX", seconds));
}
解锁关键逻辑:
public static boolean releaseLock(String key, String uniqueId) {
String luaScript = "if redis.call('get', KEYS[1]) == ARGV[1] then " +
"return redis.call('del', KEYS[1]) else return 0 end";
return jedis.eval(
luaScript,
Collections.singletonList(key),
Collections.singletonList(uniqueId)
).equals(1L);
}
上面一般中小公司,不是高并发场景,是可以使用的。单机redis小业务也撑得住
4、多机案例
1、基于setnx的分布式锁有什么缺点?
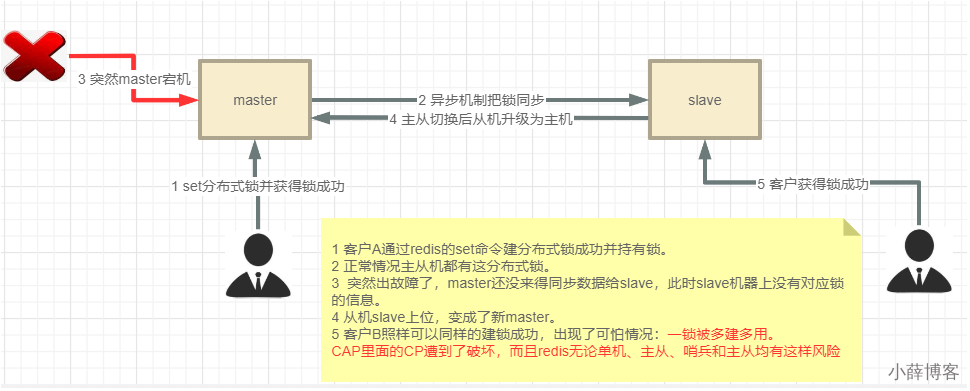
线程 1 首先获取锁成功,将键值对写入 redis 的 master 节点;
在 redis 将该键值对同步到 slave 节点之前,master 发生了故障;
redis 触发故障转移,其中一个 slave 升级为新的 master;
此时新的 master 并不包含线程 1 写入的键值对,因此线程 2 尝试获取锁也可以成功拿到锁;
此时相当于有两个线程获取到了锁,可能会导致各种预期之外的情况发生,例如最常见的脏数据。
我们加的是排它独占锁,同一时间只能有一个建redis锁成功并持有锁,严禁出现2个以上的请求线程拿到锁。危险的
2、redis之父提出了Redlock算法解决这个问题
Redis也提供了Redlock算法,用来实现基于多个实例的分布式锁。
锁变量由多个实例维护,即使有实例发生了故障,锁变量仍然是存在的,客户端还是可以完成锁操作。Redlock算法是实现高可靠分布式锁的一种有效解决方案,可以在实际开发中使用。
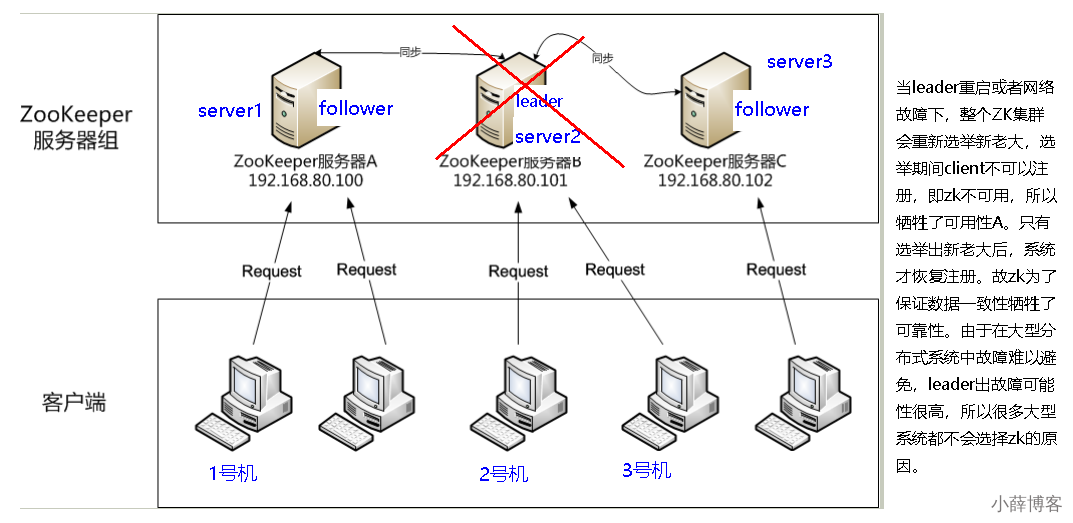
3、Redis、Zookeeper、Eureka集群比较
1、Zookeeper集群 -- CP
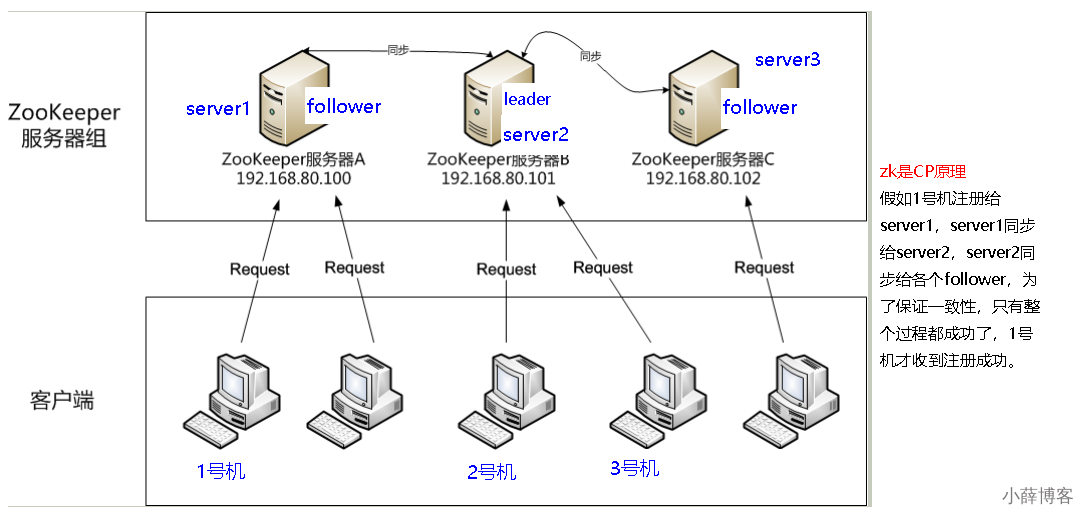
2、Eureka集群 -- AP

3、Redis集群 -- AP
redis异步复制造成的锁丢失,
比如:主节点没来的及把刚刚set进来这条数据给从节点,就挂了。
5、设计理念
该方案也是基于(set 加锁、Lua 脚本解锁)进行改良的,所以redis之父antirez 只描述了差异的地方,大致方案如下。
假设我们有N个Redis主节点,例如 N = 5这些节点是完全独立的,我们不使用复制或任何其他隐式协调系统,为了取到锁客户端执行以下操作:
| 1 | 获取当前时间,以毫秒为单位; |
|---|---|
| 2 | 依次尝试从5个实例,使用相同的 key 和随机值(例如 UUID)获取锁。当向Redis 请求获取锁时,客户端应该设置一个超时时间,这个超时时间应该小于锁的失效时间。例如你的锁自动失效时间为 10 秒,则超时时间应该在 5-50 毫秒之间。这样可以防止客户端在试图与一个宕机的 Redis 节点对话时长时间处于阻塞状态。如果一个实例不可用,客户端应该尽快尝试去另外一个 Redis 实例请求获取锁; |
| 3 | 客户端通过当前时间减去步骤 1 记录的时间来计算获取锁使用的时间。当且仅当从大多数(N/2+1,这里是 3 个节点)的 Redis 节点都取到锁,并且获取锁使用的时间小于锁失效时间时,锁才算获取成功; |
| 4 | 如果取到了锁,其真正有效时间等于初始有效时间减去获取锁所使用的时间(步骤 3 计算的结果)。 |
| 5 | 如果由于某些原因未能获得锁(无法在至少 N/2 + 1 个 Redis 实例获取锁、或获取锁的时间超过了有效时间),客户端应该在所有的 Redis 实例上进行解锁(即便某些Redis实例根本就没有加锁成功,防止某些节点获取到锁但是客户端没有得到响应而导致接下来的一段时间不能被重新获取锁)。 |
该方案为了解决数据不一致的问题,直接舍弃了异步复制只使用 master 节点,同时由于舍弃了 slave,为了保证可用性,引入了 N 个节点,官方建议是 5。本次用3台实例来做说明。
客户端只有在满足下面的这两个条件时,才能认为是加锁成功。
条件1:客户端从超过半数(大于等于N/2+1)的Redis实例上成功获取到了锁;
条件2:客户端获取锁的总耗时没有超过锁的有效时间。
为什么是奇数? N = 2X + 1 (N是最终部署机器数,X是容错机器数)
1 先知道什么是容错
失败了多少个机器实例后我还是可以容忍的,所谓的容忍就是数据一致性还是可以Ok的,CP数据一致性还是可以满足
加入在集群环境中,redis失败1台,可接受。2X+1 = 2 * 1+1 =3,部署3台,死了1个剩下2个可以正常工作,那就部署3台。
加入在集群环境中,redis失败2台,可接受。2X+1 = 2 * 2+1 =5,部署5台,死了2个剩下3个可以正常工作,那就部署5台。
2 为什么是奇数?
最少的机器,最多的产出效果
加入在集群环境中,redis失败1台,可接受。2N+2= 2 * 1+2 =4,部署4台
加入在集群环境中,redis失败2台,可接受。2N+2 = 2 * 2+2 =6,部署6台
1、案例
- docker走起3台redis的master机器,本次设置3台master各自独立无从属关系
docker run -p 6381:6379 --name redis-master-1 -d redis:6.0.7
docker run -p 6382:6379 --name redis-master-2 -d redis:6.0.7
docker run -p 6383:6379 --name redis-master-3 -d redis:6.0.7
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<!--<version>3.12.0</version>-->
<version>3.13.4</version>
</dependency>
spring.application.name=spring-boot-redis
server.port=9090
spring.swagger2.enabled=true
spring.redis.database=0
spring.redis.password=
spring.redis.timeout=3000
#sentinel/cluster/single
spring.redis.mode=single
spring.redis.pool.conn-timeout=3000
spring.redis.pool.so-timeout=3000
spring.redis.pool.size=10
spring.redis.single.address1=192.168.111.147:6381
spring.redis.single.address2=192.168.111.147:6382
spring.redis.single.address3=192.168.111.147:6383
@Configuration
@EnableConfigurationProperties(RedisProperties.class)
public class CacheConfiguration {
@Autowired
RedisProperties redisProperties;
@Bean
RedissonClient redissonClient1() {
Config config = new Config();
String node = redisProperties.getSingle().getAddress1();
node = node.startsWith("redis://") ? node : "redis://" + node;
SingleServerConfig serverConfig = config.useSingleServer()
.setAddress(node)
.setTimeout(redisProperties.getPool().getConnTimeout())
.setConnectionPoolSize(redisProperties.getPool().getSize())
.setConnectionMinimumIdleSize(redisProperties.getPool().getMinIdle());
if (StringUtils.isNotBlank(redisProperties.getPassword())) {
serverConfig.setPassword(redisProperties.getPassword());
}
return Redisson.create(config);
}
@Bean
RedissonClient redissonClient2() {
Config config = new Config();
String node = redisProperties.getSingle().getAddress2();
node = node.startsWith("redis://") ? node : "redis://" + node;
SingleServerConfig serverConfig = config.useSingleServer()
.setAddress(node)
.setTimeout(redisProperties.getPool().getConnTimeout())
.setConnectionPoolSize(redisProperties.getPool().getSize())
.setConnectionMinimumIdleSize(redisProperties.getPool().getMinIdle());
if (StringUtils.isNotBlank(redisProperties.getPassword())) {
serverConfig.setPassword(redisProperties.getPassword());
}
return Redisson.create(config);
}
@Bean
RedissonClient redissonClient3() {
Config config = new Config();
String node = redisProperties.getSingle().getAddress3();
node = node.startsWith("redis://") ? node : "redis://" + node;
SingleServerConfig serverConfig = config.useSingleServer()
.setAddress(node)
.setTimeout(redisProperties.getPool().getConnTimeout())
.setConnectionPoolSize(redisProperties.getPool().getSize())
.setConnectionMinimumIdleSize(redisProperties.getPool().getMinIdle());
if (StringUtils.isNotBlank(redisProperties.getPassword())) {
serverConfig.setPassword(redisProperties.getPassword());
}
return Redisson.create(config);
}
/**
* 单机
* @return
*/
/*@Bean
public Redisson redisson()
{
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.111.147:6379").setDatabase(0);
return (Redisson) Redisson.create(config);
}*/
@Data
public class RedisPoolProperties {
private int maxIdle;
private int minIdle;
private int maxActive;
private int maxWait;
private int connTimeout;
private int soTimeout;
/**
* 池大小
*/
private int size;
}
@Data
public class RedisPoolProperties {
private int maxIdle;
private int minIdle;
private int maxActive;
private int maxWait;
private int connTimeout;
private int soTimeout;
/**
* 池大小
*/
private int size;
}
@Data
public class RedisSingleProperties {
private String address1;
private String address2;
private String address3;
}
@RestController
@Slf4j
public class RedLockController {
public static final String CACHE_KEY_REDLOCK = "xx_REDLOCK";
@Autowired
RedissonClient redissonClient1;
@Autowired
RedissonClient redissonClient2;
@Autowired
RedissonClient redissonClient3;
@GetMapping(value = "/redlock")
public void getlock() {
//CACHE_KEY_REDLOCK为redis 分布式锁的key
RLock lock1 = redissonClient1.getLock(CACHE_KEY_REDLOCK);
RLock lock2 = redissonClient2.getLock(CACHE_KEY_REDLOCK);
RLock lock3 = redissonClient3.getLock(CACHE_KEY_REDLOCK);
RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3);
boolean isLock;
try {
//waitTime 锁的等待时间处理,正常情况下 等5s
//leaseTime就是redis key的过期时间,正常情况下等5分钟。
isLock = redLock.tryLock(5, 300, TimeUnit.SECONDS);
log.info("线程{},是否拿到锁:{} ",Thread.currentThread().getName(),isLock);
if (isLock) {
//TODO if get lock success, do something;
//暂停20秒钟线程
try { TimeUnit.SECONDS.sleep(20); } catch (InterruptedException e) { e.printStackTrace(); }
}
} catch (Exception e) {
log.error("redlock exception ",e);
} finally {
// 无论如何, 最后都要解锁
redLock.unlock();
System.out.println(Thread.currentThread().getName()+"\t"+"redLock.unlock()");
}
}
}10、你觉得 Redlock 有什么问题呢?
Redlock是Redis官方提出的一种分布式锁算法,它的设计初衷是为了解决在分布式系统中实现可靠的互斥锁的问题。虽然Redlock在理论上看起来非常可靠,但是在实际使用中存在以下问题:
- 非确定性:Redlock算法的可靠性依赖于多个Redis节点之间的同步性和时钟同步性,如果其中一个Redis节点的时钟偏移过大,就可能导致锁的非确定性,这会给系统带来不可预测的风险。
- 高延迟:Redlock算法需要对多个Redis节点进行访问和同步,这会导致锁的获取和释放的延迟较高,尤其是在网络延迟较大的情况下,会影响系统的响应速度和性能。
- 可重入性问题:Redlock算法没有考虑锁的可重入性,如果同一个线程多次请求同一个锁,就有可能发生死锁或者锁失效的情况。
- 不支持阻塞式锁:Redlock算法只支持非阻塞式锁,如果一个线程无法获取锁,就需要不断重试,这会导致锁的争用和系统的性能下降。
综上所述,虽然Redlock算法在理论上看起来非常可靠,但是在实际使用中存在一些问题,需要根据具体情况进行评估和选择,或者采用其他更加可靠的分布式锁算法来替代Redlock算法。
11、Redis如何做分布式锁
Redis 可以使用 setnx 命令来实现分布式锁。setnx 命令原子地设置一个键的值,如果该键不存在,则设置成功并返回 1,否则设置失败并返回 0。利用这个机制,可以将 Redis 的一个字符串类型的键作为锁,并使用 setnx 命令尝试获取锁。
基本的实现流程如下:
- 尝试获取锁:客户端向 Redis 发送 setnx 命令,将一个字符串键设置为锁,在命令执行成功时获得锁。
- 执行业务逻辑:获取锁后,客户端可以执行一些需要互斥的业务逻辑。
- 释放锁:当客户端完成业务逻辑后,使用 del 命令将锁删除,从而释放锁。
需要注意以下几点:
- 在获取锁时,需要设置一个过期时间,以防止锁被永久保留(例如出现异常错误)。可以使用 expire 命令或 set 命令的 EX 参数来设置过期时间。
- 建议使用随机数或进程 ID 等信息作为锁的值,从而确保每个客户端的锁都是唯一的。
- 为了避免死锁和其他竞态条件问题,建议在释放锁之前先检查锁是否属于当前客户端。可以使用 get 命令获取锁的值并比较。
- 在高并发情况下,可能会出现多个客户端同时请求锁的情况,可以使用 Lua 脚本等机制来确保原子性操作。
12、使用 setnx 做分布式锁会出现什么问题
在使用 setnx 做分布式锁时,可能会出现以下问题:
死锁:如果一个线程获得了锁但没有释放它,那么其他线程将无法获取该锁,从而导致死锁。
竞态条件:多个线程同时请求锁,可能会导致多个线程都尝试获取锁并成功,从而破坏了锁的互斥性。
并发问题:当多个线程尝试获得锁时,可能会导致竞争和阻塞,从而降低系统性能。
过期时间: 过期时间不定,不好设置,会出现锁提前释放
可重入性问题:如果一个线程已经获取了锁并再次尝试获取锁,这可能会导致死锁或其他不可预测的行为。
13、使用 redisson 做分布式锁
Redisson 是一个基于 Redis 的分布式 Java 对象和服务框架,它提供了一些强大的分布式锁功能,可以帮助我们更安全、高效地实现分布式锁。
使用 Redisson 实现分布式锁的步骤如下:
- 引入 Redisson 依赖:在项目中引入 Redisson 的相应依赖,并配置 Redisson 的连接参数。
- 创建 RedissonClient:通过 Redisson 的 Config 类配置 RedissonClient,包括 Redis 的 host、port、password 等信息。
- 获取锁:使用 RedissonClient 的 getLock 方法获取锁对象。可以选择使用公平锁或非公平锁,也可以设置锁的过期时间。
- 执行业务逻辑:获取锁后,客户端可以执行一些需要互斥的业务逻辑。
- 释放锁:当客户端完成业务逻辑后,使用 unlock 方法释放锁。如果不手动释放锁,则 Redisson 会自动在锁超时后释放锁。
// 创建 Redisson 客户端
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379").setPassword("password");
RedissonClient redisson = Redisson.create(config);
// 获取分布式锁
RLock lock = redisson.getLock("mylock");
try {
// 尝试获取锁,最多等待 10 秒钟,锁的过期时间为 30 秒钟
boolean res = lock.tryLock(10, 30, TimeUnit.SECONDS);
if (res) {
// 成功获取锁,执行业务逻辑
// ...
}
} finally {
// 释放锁
lock.unlock();
}需要注意以下几点:
- Redisson 支持多种类型的锁,包括公平锁、非公平锁、可重入锁等。在选择锁类型时,需要根据具体需求和场景进行选择。
- 在高并发场景中,可能会出现死锁或锁争用问题。Redisson 提供了一些机制来避免这些问题,如重试次数、看门狗等。
14、Redis与zookpeer做分布式锁有什么区别
Redis和Zookeeper都可以用于实现分布式锁,但它们有以下几点区别:
- 数据存储方式不同:Redis是内存型数据库,数据存储在内存中,支持持久化,读写速度快;而Zookeeper是一个文件系统,数据存储在磁盘上,读写速度较慢。
- 锁的实现方式不同:Redis通过setnx命令和Lua脚本实现分布式锁,具有一定的性能优势;而Zookeeper通过临时节点和Watch机制实现分布式锁,可靠性更高。
- 依赖的第三方库不同:Redis需要使用Java客户端或者其它语言的客户端来连接Redis服务端,而Zookeeper则使用Curator库进行连接和操作。
- 锁的可重入性和释放机制不同: Redis支持可重入锁和自动释放锁;Zookeeper不支持可重入锁,在锁释放时需要手动删除节点。
总之,Redis和Zookeeper都有各自的优缺点和适用场景。当需要考虑到分布式锁的可靠性和一致性时,Zookeeper可以作为更好的选择;而如果需要高并发下的性能和简单易用性,则Redis可能更适合。
15、Redis分布式锁如何续期?看门狗知道吗?
1、code
public class WatchDogDemo
{
public static final String LOCKKEY = "AAA";
private static Config config;
private static Redisson redisson;
static {
config = new Config();
config.useSingleServer().setAddress("redis://"+"192.168.111.147"+":6379").setDatabase(0);
redisson = (Redisson)Redisson.create(config);
}
public static void main(String[] args)
{
RLock redissonLock = redisson.getLock(LOCKKEY);
redissonLock.lock();
try
{
System.out.println("1111");
//暂停几秒钟线程
try { TimeUnit.SECONDS.sleep(25); } catch (InterruptedException e) { e.printStackTrace(); }
}catch (Exception e){
e.printStackTrace();
}finally {
redissonLock.unlock();
}
System.out.println(Thread.currentThread().getName() + " main ------ ends.");
//暂停几秒钟线程
try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); }
redisson.shutdown();
}
}2、缓存续命
Redis 分布式锁过期了,但是业务逻辑还没处理完怎么办
- 守护线程“续命”
额外起一个线程,定期检查线程是否还持有锁,如果有则延长过期时间。
Redisson 里面就实现了这个方案,使用“看门狗”定期检查(每1/3的锁时间检查1次),如果线程还持有锁,则刷新过期时间;
分布式难以避免的,系统时钟影响
如果线程 1 从 3 个实例获取到了锁。但是这 3 个实例中的某个实例的系统时间走的稍微快一点,则它持有的锁会提前过期被释放,当他释放后,此时又有 3 个实例是空闲的,则线程2也可以获取到锁,则可能出现两个线程同时持有锁了。
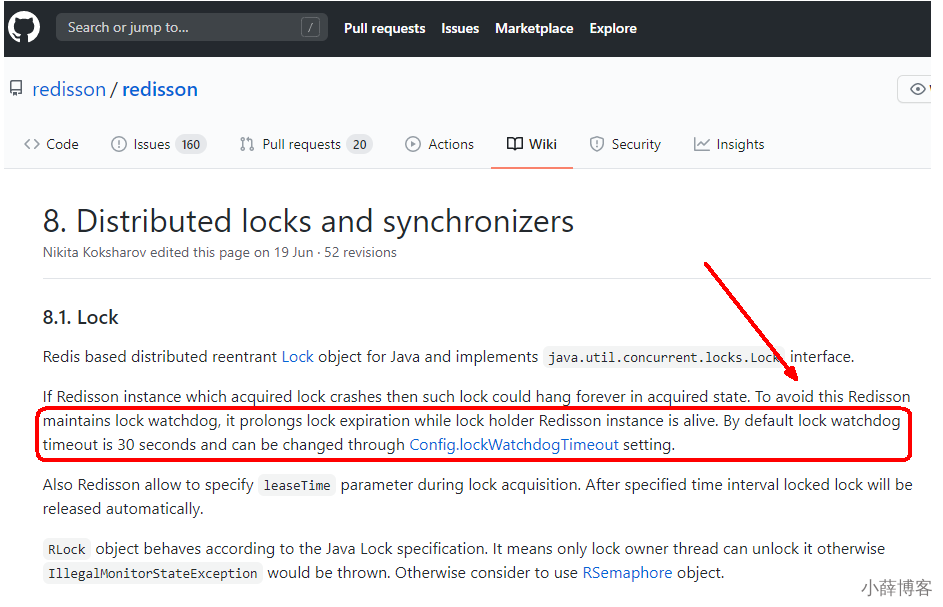
3、watchdog
在获取锁成功后,给锁加一个 watchdog,watchdog 会起一个定时任务,在锁没有被释放且快要过期的时候会续期

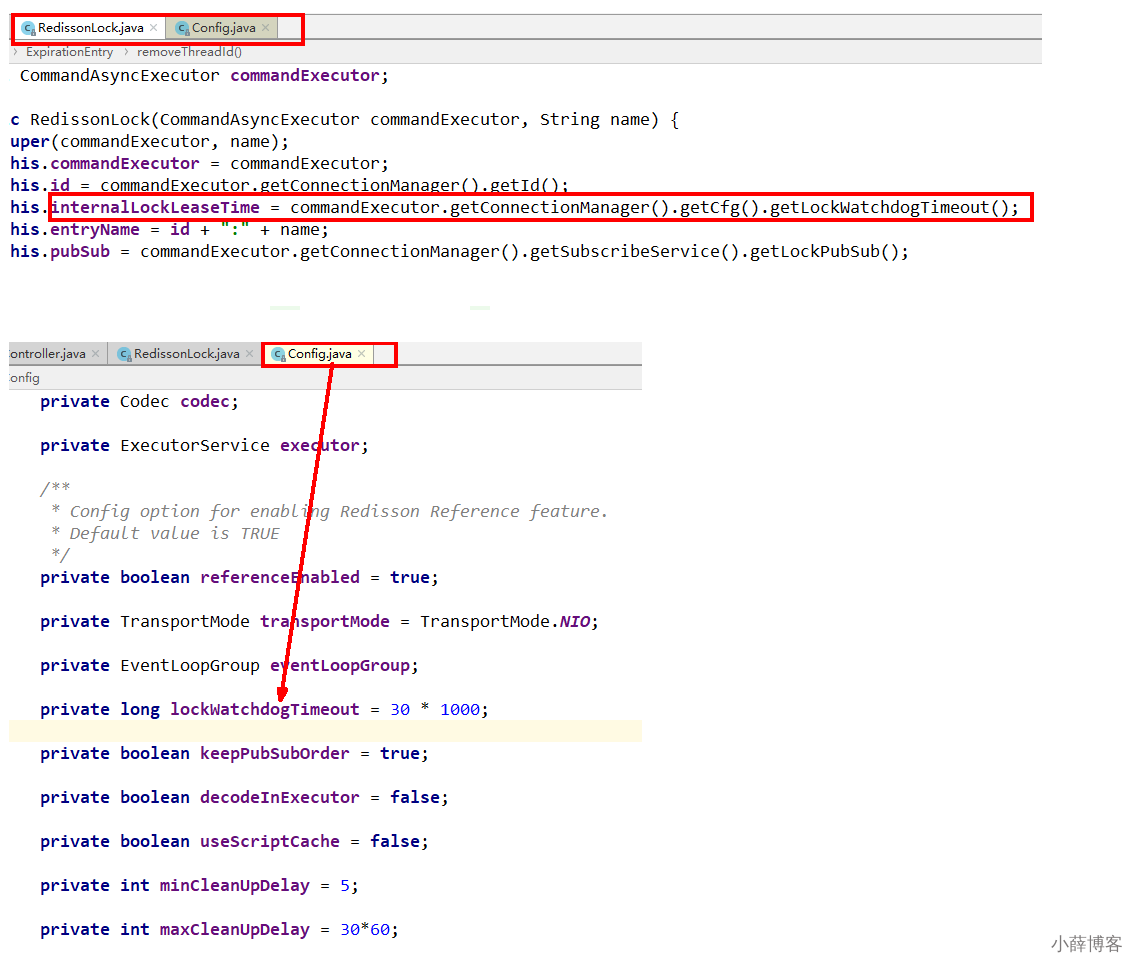
4、源码解析
1、分析1 - 通过redisson新建出来的锁key,默认是30秒
2、分析2
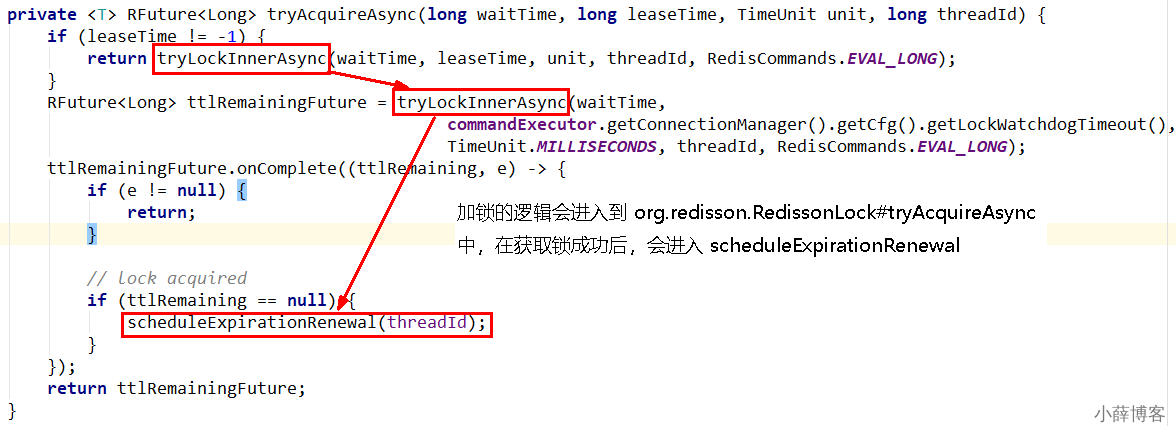
3、分析3
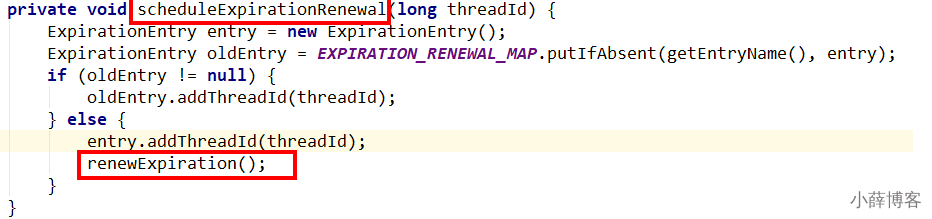
这里面初始化了一个定时器,dely 的时间是 internalLockLeaseTime/3。
在 Redisson 中,internalLockLeaseTime 是 30s,也就是每隔 10s 续期一次,每次 30s。
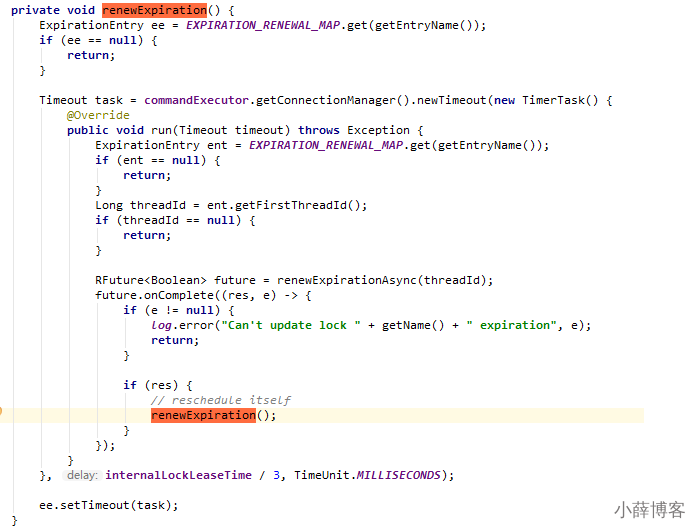
4、分析4 - watch dog自动延期机制
客户端A加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端A还持有锁key,那么就会不断的延长锁key的生存时间,默认每次续命又从30秒新开始
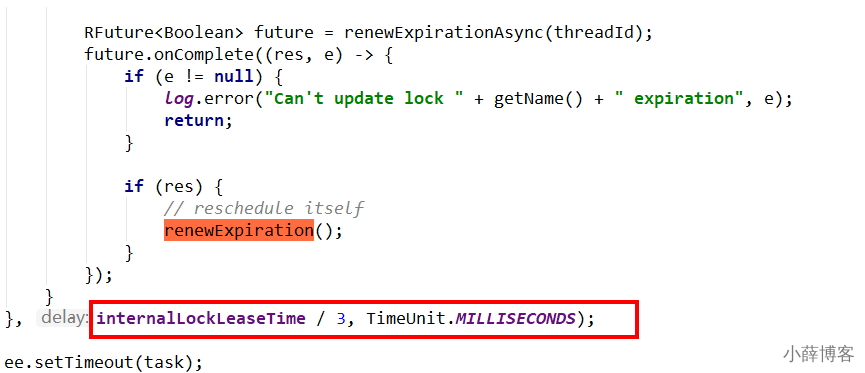
5、分析5
| KEYS[1]代表的是你加锁的那个key | RLock redissonLock = redisson.getLock("lockxx");这里你自己设置了加锁的那个锁key |
|---|---|
| ARGV[2]代表的是加锁的客户端的ID |  |
| ARGV[1]就是锁key的默认生存时间 | 默认30秒 |
| 如何加锁 | 你要加锁的那个锁key不存在的话,你就进行加锁hincrby 7bcf6a9f-e7f7-49b0-9727-141df3b88038:117 1接着会执行 pexpire lockxx 30000 |
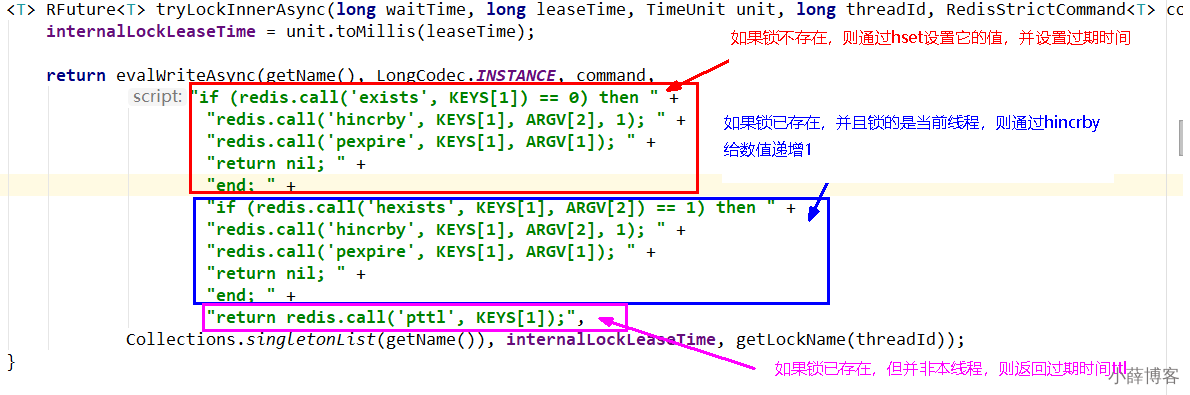
6、流程解释
- 通过exists判断,如果锁不存在,则设置值和过期时间,加锁成功
- 通过hexists判断,如果锁已存在,并且锁的是当前线程,则证明是重入锁,加锁成功
- 如果锁已存在,但锁的不是当前线程,则证明有其他线程持有锁。返回当前锁的过期时间(代表了lockxx这个锁key的剩余生存时间),加锁失败
7、加锁查看
package com.xx.redis.test;
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.config.Config;
import java.util.concurrent.TimeUnit;
public class WatchDogDemo
{
public static final String LOCKKEY = "AAA";
private static Config config;
private static Redisson redisson;
static {
config = new Config();
config.useSingleServer().setAddress("redis://"+"192.168.111.147"+":6379").setDatabase(0);
redisson = (Redisson)Redisson.create(config);
}
public static void main(String[] args)
{
RLock redissonLock = redisson.getLock(LOCKKEY);
redissonLock.lock();
try
{
System.out.println("1111");
//暂停几秒钟线程
try { TimeUnit.SECONDS.sleep(25); } catch (InterruptedException e) { e.printStackTrace(); }
}catch (Exception e){
e.printStackTrace();
}finally {
if (redissonLock.isLocked() && redissonLock.isHeldByCurrentThread()) {
redissonLock.unlock();
}
}
System.out.println(Thread.currentThread().getName() + " main ------ ends.");
//暂停几秒钟线程
try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); }
redisson.shutdown();
}
}
加锁成功后,在redis的内存数据中,就有一条hash结构的数据。
Key为锁的名称;field为随机字符串+线程ID;值为1。见下
如果同一线程多次调用lock方法,值递增1。----------可重入锁见后
8、可重入锁查看

加大业务逻辑处理时间,看超过10秒钟后,redisson的续命加时
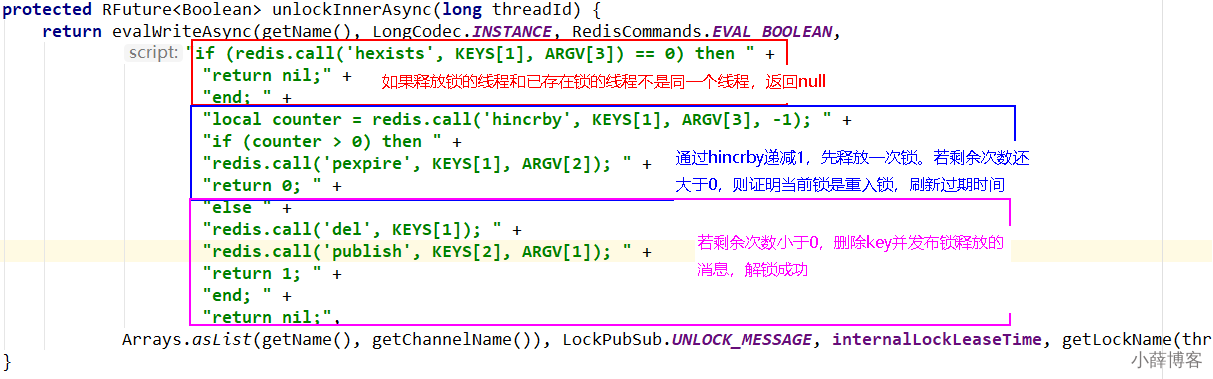
9、解锁
16、生产上你们你们的redis内存设置多少?
一般推荐Redis设置内存为最大物理内存的四分之三
Redis的内存设置应该根据具体的应用场景和需求来进行调整。一般来说,需要考虑以下几个方面:
- 数据量:根据需要存储的数据量来设置Redis的内存大小,确保足够存储所有数据。
- 并发访问量:如果有大量并发访问,需要设置足够的内存来支持并发读写操作。
- 数据类型:不同的数据类型在Redis中占据的内存大小不同,需要根据实际情况来进行调整。
- 操作频率:如果某些数据经常被访问,需要分配更多的内存来加速访问。
- 可用性和可靠性:在设置Redis的内存大小时,需要考虑到系统的可用性和可靠性,确保系统在处理大量数据时不会出现宕机或数据丢失的情况。
因此,对于生产环境的Redis内存设置,需要根据具体的业务需求和系统规模进行调整,并进行充分的测试和评估,以确保Redis能够稳定运行并满足业务需求。
17、如何配置、修改redis的内存大小
1、查看Redis最大占用内存

打开redis配置文件,设置maxmemory参数,maxmemory是bytes字节类型,注意转换。
2、redis默认内存多少可以用?

3、一般生产上你如何配置?
一般推荐Redis设置内存为最大物理内存的四分之三
因为Redis内存的设置需要根据具体的业务需求和系统规模来调整,不同的应用场景和业务负载下,Redis内存的设置可能会有所不同。
一般来说,Redis的内存设置应该考虑以下几个因素:
- 数据量大小:根据业务数据量大小来确定Redis的内存大小,通常建议将Redis的内存大小设置为业务数据量的1.5倍以上,以确保系统的高效和稳定。
- 并发请求量:根据系统的并发请求量来调整Redis的内存大小,通常建议将Redis的内存大小设置为能够支持最高并发请求量的2倍以上,以确保系统的高性能和可靠性。
- 数据类型和访问频率:根据不同的数据类型和访问频率,对Redis的内存大小进行合理的分配,将访问频率较高的数据存储在内存中,访问频率较低的数据存储在磁盘中,以最大程度地减少内存的占用和提高系统的性能。
需要注意的是,Redis内存的设置需要综合考虑多方面的因素,包括系统规模、业务负载、数据类型和访问频率等因素,同时需要进行实时监控和调整,以保证系统的高效和稳定。
4、如何修改redis内存设置
- 通过修改文件配置

- 通过命令修改

18、Redis清理内存的方式?定期删除和惰性删除了解过吗
1、三种不同的删除策略
如果一个键是过期的,那它到了过期时间之后是不是马上就从内存中被被删除呢??
NO
1、立即删除
Redis不可能时时刻刻遍历所有被设置了生存时间的key,来检测数据是否已经到达过期时间,然后对它进行删除。
立即删除能保证内存中数据的最大新鲜度,因为它保证过期键值会在过期后马上被删除,其所占用的内存也会随之释放。但是立即删除对cpu是最不友好的。因为删除操作会占用cpu的时间,如果刚好碰上了cpu很忙的时候,比如正在做交集或排序等计算的时候,就会给cpu造成额外的压力,让CPU心累,时时需要删除,忙死。。。。。。。这会产生大量的性能消耗,同时也会影响数据的读取操作。
总结:对CPU不友好,用处理器性能换取存储空间 (拿时间换空间)
2、惰性删除
数据到达过期时间,不做处理。等下次访问该数据时,
如果未过期,返回数据 ;
发现已过期,删除,返回不存在。
惰性删除策略的缺点是,它对内存是最不友好的
如果一个键已经过期,而这个键又仍然保留在redis中,那么只要这个过期键不被删除,它所占用的内存就不会释放。
在使用惰性删除策略时,如果数据库中有非常多的过期键,而这些过期键又恰好没有被访问到的话,那么它们也许永远也不会被删除(除非用户手动执行FLUSHDB),我们甚至可以将这种情况看作是一种内存泄漏–无用的垃圾数据占用了大量的内存,而服务器却不会自己去释放它们,这对于运行状态非常依赖于内存的Redis服务器来说,肯定不是一个好消息
总结:对memory不友好,用存储空间换取处理器性能(拿空间换时间)
3、定期删除
定期删除策略是前两种策略的折中:
定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度
特点1:CPU性能占用设置有峰值,检测频度可自定义设置
特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理
总结:周期性抽查存储空间 (随机抽查,重点抽查)
redis默认每个100ms检查,是否有过期的key,有过期key则删除。注意:redis不是每隔100ms将所有的key检查一次而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis直接进去ICU)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
定期删除策略的难点是确定删除操作执行的时长和频率:如果删除操作执行得太频繁,或者执行的时间太长,定期删除策略就会退化成立即删除策略,以至于将CPU时间过多地消耗在删除过期键上面。如果删除操作执行得太少,或者执行的时间太短,定期删除策略又会和惰性删除束略一样,出现浪费内存的情况。因此,如果采用定期删除策略的话,服务器必须根据情况,合理地设置删除操作的执行时长和执行频率。
总结:定期抽样key,判断是否过期 会有漏网之鱼
1 定期删除时,从来没有被抽查到
2 惰性删除时,也从来没有被点中使用过
上述2步骤======> 大量过期的key堆积在内存中,导致redis内存空间紧张或者很快耗尽
19、Redis缓存淘汰策略
1、noeviction: 不会驱逐任何key
2、allkeys-lru: 对所有key使用LRU算法进行删除
3、volatile-lru: 对所有设置了过期时间的key使用LRU算法进行删除
4、allkeys-random: 对所有key随机删除
5、volatile-random: 对所有设置了过期时间的key随机删除
6、volatile-ttl: 删除马上要过期的key
7、allkeys-lfu: 对所有key使用LFU算法进行删除
8、volatile-lfu: 对所有设置了过期时间的key使用LFU算法进行删除
9、总结
2 * 4 得8
2个维度
- 过期键中筛选
- 所有键中筛选
4个方面
- LRU
- LFU
- random
- ttl
10、生产用哪个
allkeys-lru20、Redis的LRU了解过吗
LRU(Least Recently Used,最近最少使用)是Redis中一种常用的缓存淘汰策略。LRU策略会优先淘汰最近最少使用的缓存对象,从而保留最近使用频率较高的缓存对象,以提高缓存的命中率和性能。
在Redis中,LRU策略的实现是通过一个双向链表和一个哈希表来完成的。哈希表中存储了缓存对象的键和指向双向链表中对应节点的指针,双向链表中存储了缓存对象的值和上一次访问时间等信息。
当缓存对象需要淘汰时,Redis会从双向链表的尾部开始查找最近最少使用的缓存对象,并将其从哈希表和双向链表中同时删除。当有新的缓存对象加入时,Redis会将其插入双向链表的头部,并在哈希表中添加对应的键和指针。
需要注意的是,Redis中的LRU策略并不是完全精确的,因为它只能根据上一次访问时间来判断缓存对象的使用频率,在某些情况下可能会导致一些较为频繁访问但访问时间较久远的缓存对象被误判为“冷数据”,因此在实际使用中,需要根据具体的业务场景来选择合适的缓存淘汰策略。
21、你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
1、canal
1、简介
canal [kə'næl],中文翻译为 水道/管道/沟渠/运河,主要用途是用于 MySQL 数据库增量日志数据的订阅、消费和解析,是阿里巴巴开发并开源的,采用Java语言开发;
历史背景是早期阿里巴巴因为杭州和美国双机房部署,存在跨机房数据同步的业务需求,实现方式主要是基于业务 trigger(触发器) 获取增量变更。从2010年开始,阿里巴巴逐步尝试采用解析数据库日志获取增量变更进行同步,由此衍生出了canal项目;
https://github.com/alibaba/canal
Canal是基于MySQL变更日志增量订阅和消费的组件
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
2、工作原理
1、传统MySQL主从复制工作原理
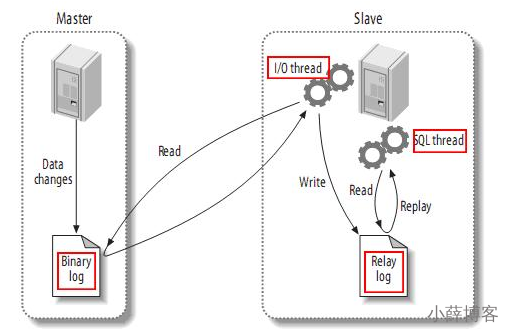
MySQL的主从复制将经过如下步骤:
1、当 master 主服务器上的数据发生改变时,则将其改变写入二进制事件日志文件中;
2、salve 从服务器会在一定时间间隔内对 master 主服务器上的二进制日志进行探测,探测其是否发生过改变,如果探测到 master 主服务器的二进制事件日志发生了改变,则开始一个 I/O Thread 请求 master 二进制事件日志;
3、同时 master 主服务器为每个 I/O Thread 启动一个dump Thread,用于向其发送二进制事件日志;
4、slave 从服务器将接收到的二进制事件日志保存至自己本地的中继日志文件中;
5、salve 从服务器将启动 SQL Thread 从中继日志中读取二进制日志,在本地重放,使得其数据和主服务器保持一致;
6、最后 I/O Thread 和 SQL Thread 将进入睡眠状态,等待下一次被唤醒;
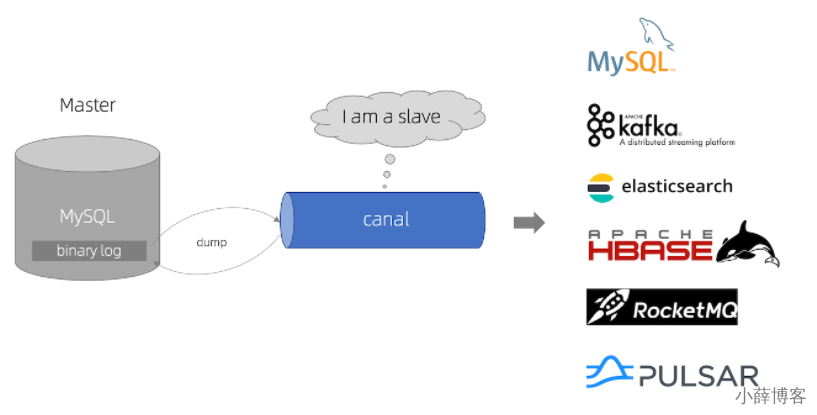
2、canal工作原理
canal 工作原理
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
canal 解析 binary log 对象(原始为 byte 流)
分布式系统只有最终一致性,很难做到强一致性
2、mysql-canal-redis双写一致性Coding
1、mysql版本5.7.28
1、脚本
CREATE TABLE `t_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`userName` varchar(100) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4;2、当前的主机二进制日志
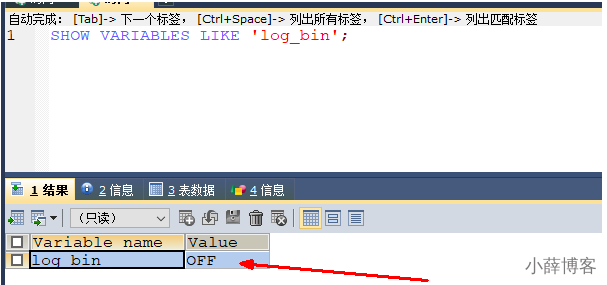
show master status;3、查看SHOW VARIABLES LIKE 'log_bin';
4、开启 MySQL的binlog写入功能
mysql安装目录
D:\devSoft\mysql\mysql5.7.28目录下打开 my.ini
最好备份
log-bin=mysql-bin #开启 binlog
binlog-format=ROW #选择 ROW 模式
server_id=1 #配置MySQL replaction需要定义,不要和canal的 slaveId重复
ROW模式 除了记录sql语句之外,还会记录每个字段的变化情况,能够清楚的记录每行数据的变化历史,但会占用较多的空间。
STATEMENT模式只记录了sql语句,但是没有记录上下文信息,在进行数据恢复的时候可能会导致数据的丢失情况;
MIX模式比较灵活的记录,理论上说当遇到了表结构变更的时候,就会记录为statement模式。当遇到了数据更新或者删除情况下就会变为row模式;
window my.ini
linux my.cnf

重启mysql
5、授权canal连接MySQL账号
mysql默认的用户在mysql库的user表里
默认没有canal账户,此处新建+授权
DROP USER 'canal'@'%';
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
GRANT ALL PRIVILEGES ON . TO 'canal'@'%' IDENTIFIED BY 'canal';
FLUSH PRIVILEGES;
SELECT * FROM mysql.user;


2、canal服务端
1、下载
2、解压后整体放入/mycanal路径下
3、配置修改
- /mycanal/canal.deployer-1.1.5/conf/example路径下

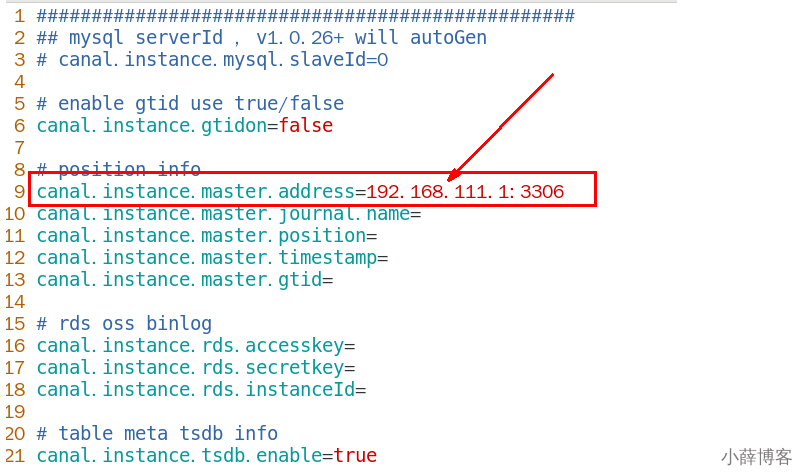
- instance.properties
- 换成自己的mysql的IP地址
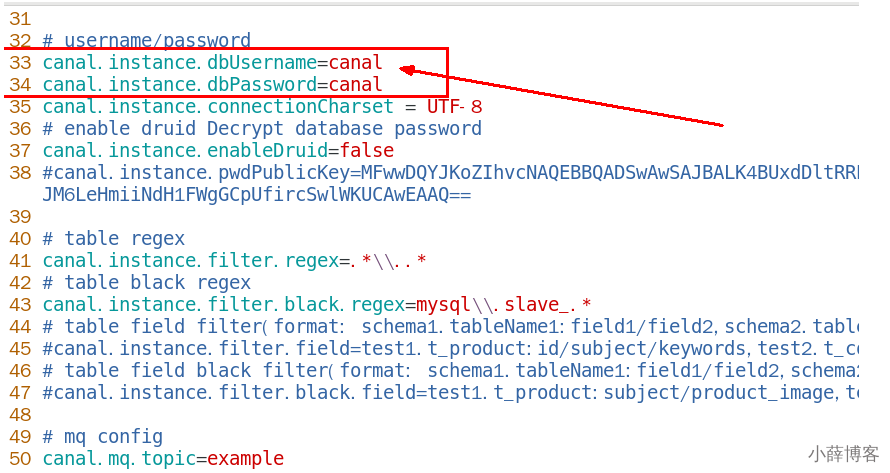
- 换成自己的在mysql新建的canal账户
- /mycanal/canal.deployer-1.1.5/bin路径下执行
- ./startup.sh
4、查看 server 日志
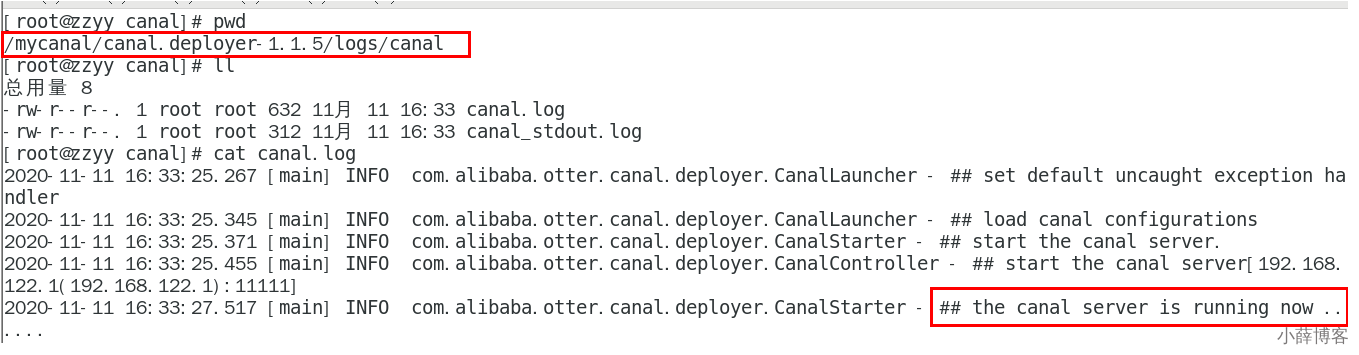
5、查看 instance 的日志

3、canal客户端(Java编写业务程序)
1、canal_demo
2、pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.5.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.xx.study</groupId>
<artifactId>canal_demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>canal_demo</name>
<description>Demo project for Spring Boot</description>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<junit.version>4.12</junit.version>
<log4j.version>1.2.17</log4j.version>
<lombok.version>1.16.18</lombok.version>
<mysql.version>5.1.47</mysql.version>
<druid.version>1.1.16</druid.version>
<mybatis.spring.boot.version>1.3.0</mybatis.spring.boot.version>
</properties>
<dependencies>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>
<!--guava-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
<!--web+actuator-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!--SpringBoot与Redis整合依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!-- jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.1.0</version>
</dependency>
<!-- springboot-aop 技术-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<!-- redisson -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.4</version>
</dependency>
<!--Mysql数据库驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<!--集成druid连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>${druid.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>${druid.version}</version>
</dependency>
<!--mybatis和springboot整合-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis.spring.boot.version}</version>
</dependency>
<!-- 添加springboot对amqp的支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<!--通用基础配置-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<optional>true</optional>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>RELEASE</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.73</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>3、yml
server.port=5555
4、RedisUtils
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class RedisUtils
{
public static JedisPool jedisPool;
static {
JedisPoolConfig jedisPoolConfig=new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMaxIdle(10);
jedisPool=new JedisPool(jedisPoolConfig,"192.168.111.147",6379);
}
public static Jedis getJedis() throws Exception {
if(null!=jedisPool){
return jedisPool.getResource();
}
throw new Exception("Jedispool is not ok");
}
/*public static void main(String[] args) throws Exception
{
try(Jedis jedis = RedisUtils.getJedis())
{
System.out.println(jedis);
jedis.set("k1","xxx2");
String result = jedis.get("k1");
System.out.println("-----result: "+result);
System.out.println(RedisUtils.jedisPool.getNumActive());//1
}catch (Exception e){
e.printStackTrace();
}
}*/
}5、RedisCanalClientExample
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import com.xx.study.util.RedisUtils;
import org.springframework.beans.factory.annotation.Autowired;
import redis.clients.jedis.Jedis;
import java.net.InetSocketAddress;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* @auther xx
* @create 2020-11-11 17:13
*/
public class RedisCanalClientExample
{
public static final Integer _60SECONDS = 60;
public static void main(String args[]) {
// 创建链接canal服务端
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("192.168.111.147",
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
//connector.subscribe(".*\\..*");
connector.subscribe("db2020.t_user");
connector.rollback();
int totalEmptyCount = 10 * _60SECONDS;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }
} else {
emptyCount = 0;
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR # parser of eromanga-event has an error,data:" + entry.toString(),e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.INSERT) {
redisInsert(rowData.getAfterColumnsList());
} else if (eventType == EventType.DELETE) {
redisDelete(rowData.getBeforeColumnsList());
} else {//EventType.UPDATE
redisUpdate(rowData.getAfterColumnsList());
}
}
}
}
private static void redisInsert(List<Column> columns)
{
JSONObject jsonObject = new JSONObject();
for (Column column : columns)
{
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
jsonObject.put(column.getName(),column.getValue());
}
if(columns.size() > 0)
{
try(Jedis jedis = RedisUtils.getJedis())
{
jedis.set(columns.get(0).getValue(),jsonObject.toJSONString());
}catch (Exception e){
e.printStackTrace();
}
}
}
private static void redisDelete(List<Column> columns)
{
JSONObject jsonObject = new JSONObject();
for (Column column : columns)
{
jsonObject.put(column.getName(),column.getValue());
}
if(columns.size() > 0)
{
try(Jedis jedis = RedisUtils.getJedis())
{
jedis.del(columns.get(0).getValue());
}catch (Exception e){
e.printStackTrace();
}
}
}
private static void redisUpdate(List<Column> columns)
{
JSONObject jsonObject = new JSONObject();
for (Column column : columns)
{
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
jsonObject.put(column.getName(),column.getValue());
}
if(columns.size() > 0)
{
try(Jedis jedis = RedisUtils.getJedis())
{
jedis.set(columns.get(0).getValue(),jsonObject.toJSONString());
System.out.println("---------update after: "+jedis.get(columns.get(0).getValue()));
}catch (Exception e){
e.printStackTrace();
}
}
}
}22、双写一致性,你先动缓存redis还是数据库mysql哪一个?why?
1、如果redis中有数据
需要和数据库中的值相同
2、如果redis中无数据
数据库中的值要是最新值
2、缓存按照操作来分,有细分2种
1、只读缓存
2、读写缓存
- 同步直写策略:写缓存时也同步写数据库,缓存和数据库中的数据⼀致;
- 对于读写缓存来说,要想保证缓存和数据库中的数据⼀致,就要采⽤同步直写策略
3、数据库和缓存一致性的几种更新策略
单线程,这样重量级的数据操作最好不要多线程
总之,我们要达到最终一致性!
我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存,达到一致性,切记以mysql的数据库写入库为准。
1、3种更新策略
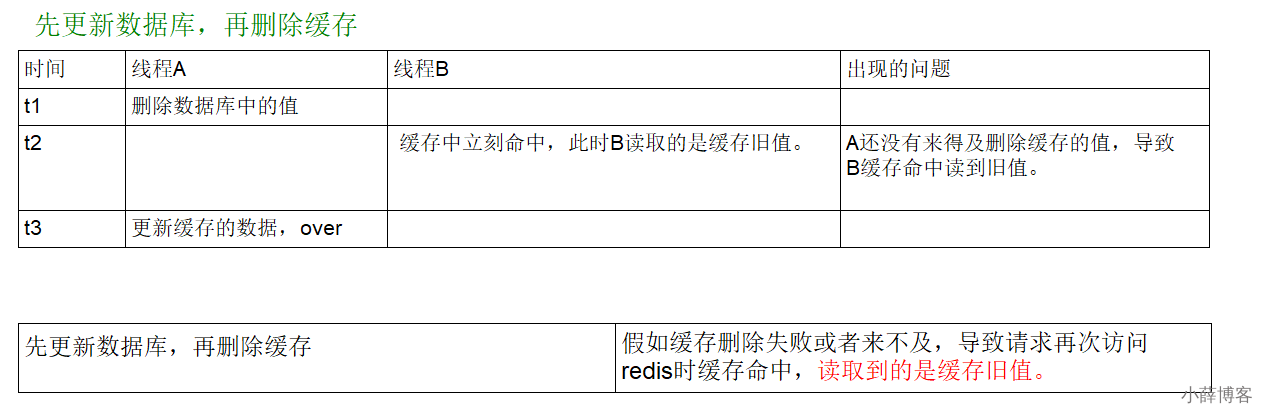
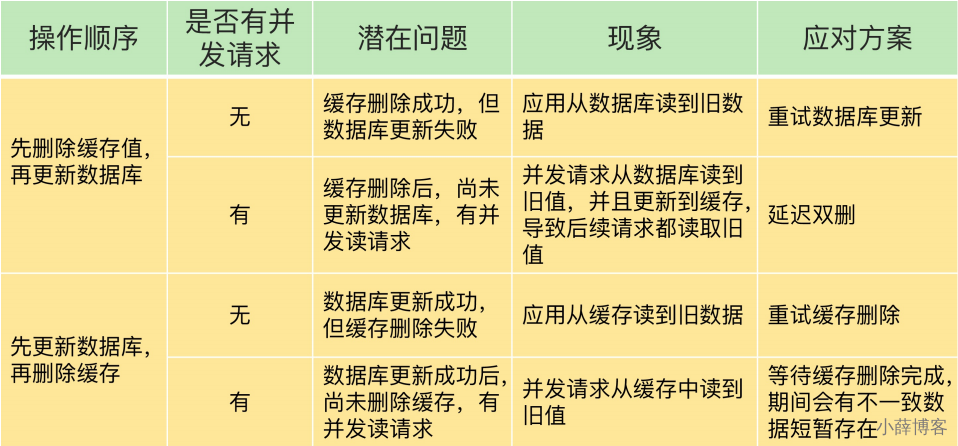
1、先更新数据库,再更新缓存
1 先更新mysql的某商品的库存,当前商品的库存是100,更新为99个。
2 先更新mysql修改为99成功,然后更新redis。3 此时假设异常出现,更新redis失败了,这导致mysql里面的库存是99而redis里面的还是100 。4 上述发生,会让数据库里面和缓存redis里面数据不一致,读到脏数据
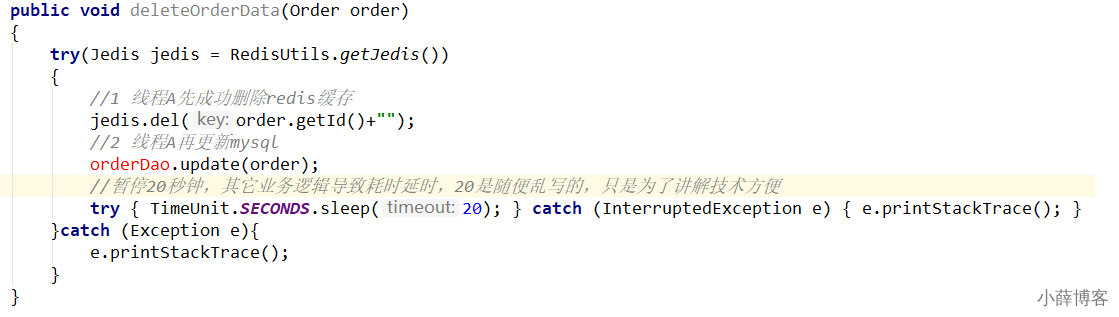
2、先删除缓存,再更新数据库
问题
这里写20秒,是自己故意乱写的,表示更新数据库可能失败,实际中不可能...O(∩_∩)O哈哈~
1 A线程先成功删除了redis里面的数据,然后去更新mysql,此时mysql正在更新中,还没有结束。(比如网络延时)
B突然出现要来读取缓存数据。
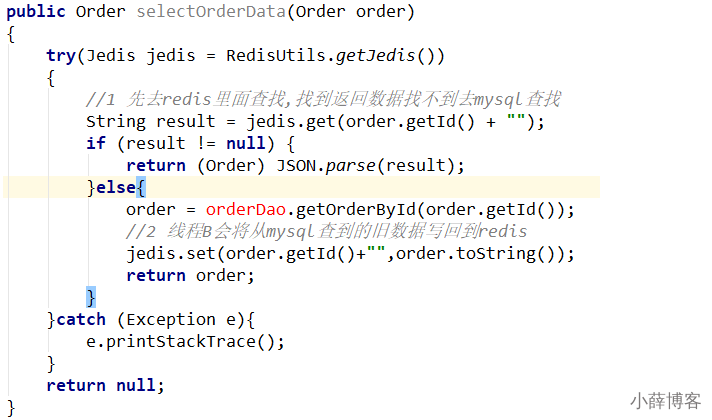
2 此时redis里面的数据是空的,B线程来读取,先去读redis里数据(已经被A线程delete掉了),此处出来2个问题:
2.1 B从mysql获得了旧值
B线程发现redis里没有(缓存缺失)马上去mysql里面读取,从数据库里面读取来的是旧值。
2.2 B会把获得的旧值写回redis
获得旧值数据后返回前台并回写进redis(刚被A线程删除的旧数据有极大可能又被写回了)。
3 A线程更新完mysql,发现redis里面的缓存是脏数据,A线程直接懵逼了,o(╥﹏╥)o
两个并发操作,一个是更新操作,另一个是查询操作,A更新操作删除缓存后,B查询操作没有命中缓存,B先把老数据读出来后放到缓存中,然后A更新操作更新了数据库。
于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还一直这样脏下去了。
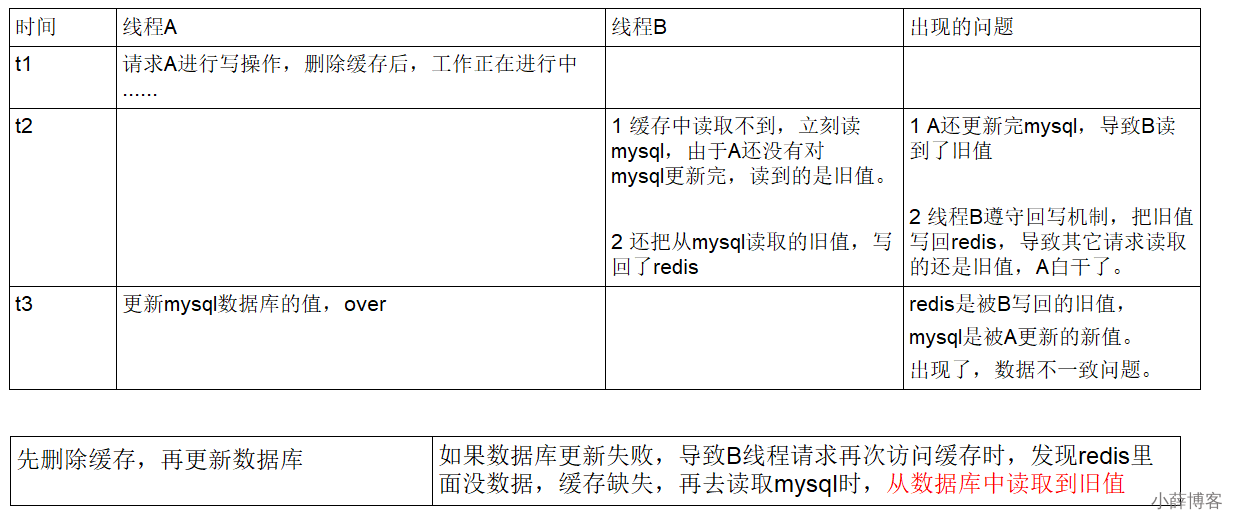
4 总结流程:
(1)请求A进行写操作,删除缓存后,工作正在进行中......A还么有彻底更新完
(2)请求B开工,查询redis发现缓存不存在
(3)请求B继续,去数据库查询得到了myslq中的旧值
(4)请求B将旧值写入redis缓存
(5)请求A将新值写入mysql数据库
上述情况就会导致不一致的情形出现。
解决方案
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。
后面的线程进来发现已经有缓存了,就直接走缓存。
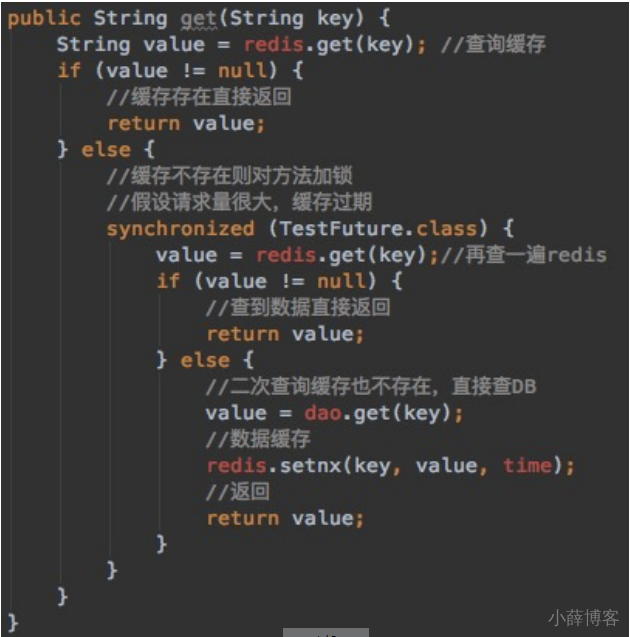
采用延时双删策略


双删方案面试题
这个删除该休眠多久呢
线程Asleep的时间,就需要大于线程B读取数据再写入缓存的时间。
这个时间怎么确定呢?
在业务程序运行的时候,统计下线程读数据和写缓存的操作时间,自行评估自己的项目的读数据业务逻辑的耗时,
以此为基础来进行估算。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上加百毫秒即可。
这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
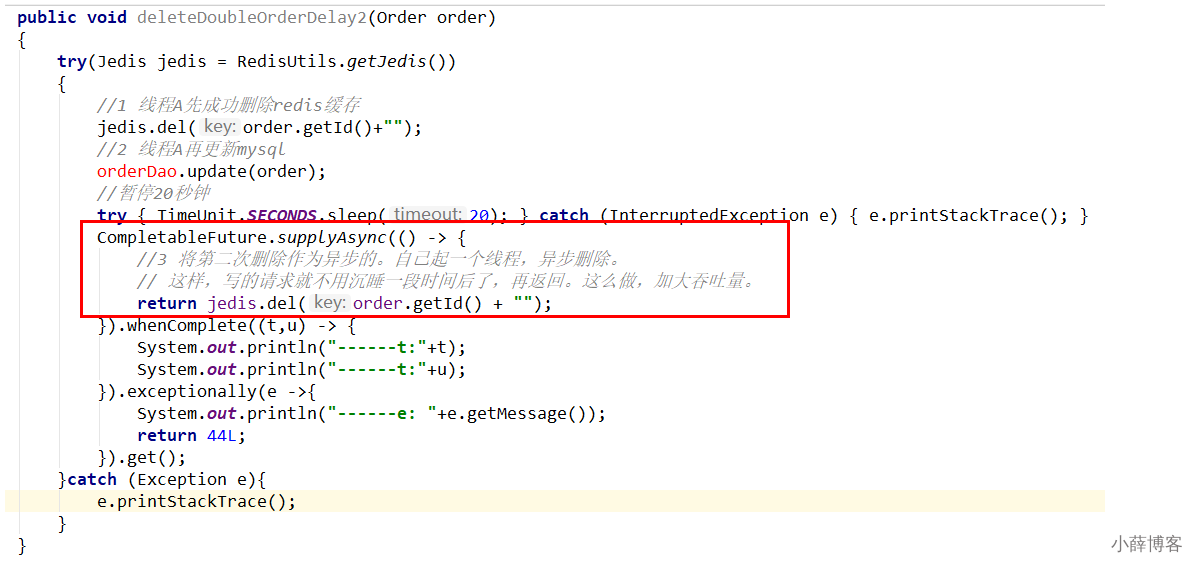
当前演示的效果是mysql单机,如果mysql主从读写分离架构如何?
(1)请求A进行写操作,删除缓存
(2)请求A将数据写入数据库了,
(3)请求B查询缓存发现,缓存没有值
(4)请求B去从库查询,这时,还没有完成主从同步,因此查询到的是旧值
(5)请求B将旧值写入缓存
(6)数据库完成主从同步,从库变为新值 上述情形,就是数据不一致的原因。还是使用双删延时策略。
只是,睡眠时间修改为在主从同步的延时时间基础上,加几百ms
这种同步淘汰策略,吞吐量降低怎么办?
3、先更新数据库,再删除缓存
业务指导思想
- 老外论文 https://docs.microsoft.com/en-us/azure/architecture/patterns/cache-aside
- 知名社交网站facebook也在论文《Scaling Memcache at Facebook》中提出 https://www.usenix.org/system/files/conference/nsdi13/nsdi13-final170_update.pdf
- 我们上面的canal也是类似的思想 上述的订阅binlog程序在mysql中有现成的中间件叫canal,可以完成订阅binlog日志的功能。
解决方案
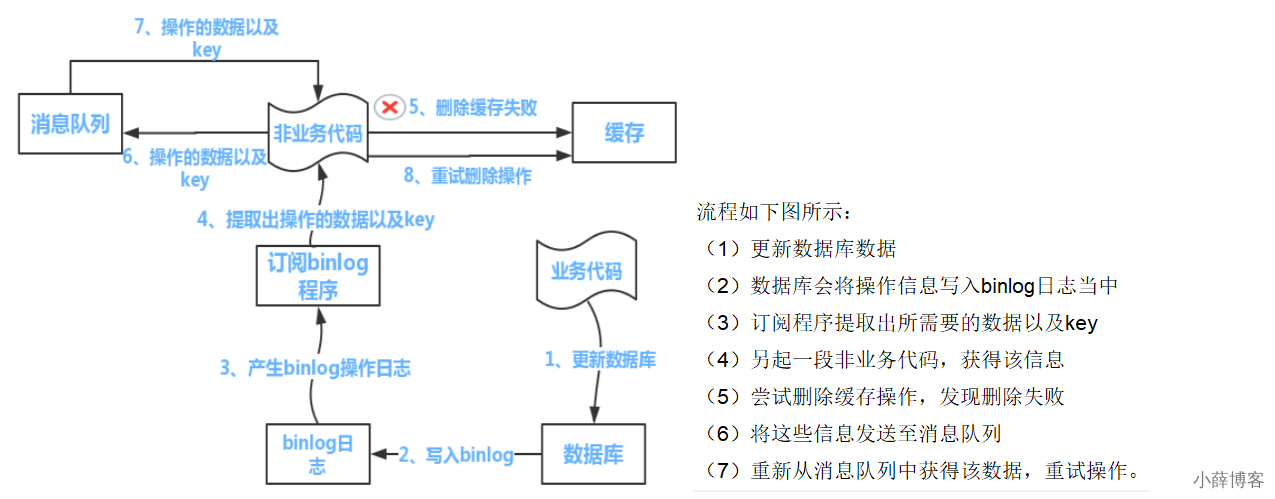
1 可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用Kafka/RabbitMQ等)。
2 当程序没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。
3 如果能够成功地删除或更新,我们就要把这些值从消息队列中去除,以免重复操作,此时,我们也可以保证数据库和缓存的数据一致了,否则还需要再次进行重试
4 如果重试超过的一定次数后还是没有成功,我们就需要向业务层发送报错信息了,通知运维人员。
4、方案2和方案3用那个?利弊如何
在大多数业务场景下,我们会把Redis作为只读缓存使用。假如定位是只读缓存来说,
理论上我们既可以先删除缓存值再更新数据库,也可以先更新数据库再删除缓存,但是没有完美方案,两害相衡趋其轻的原则
个人建议是,优先使用先更新数据库,再删除缓存的方案。理由如下:
1 先删除缓存值再更新数据库,有可能导致请求因缓存缺失而访问数据库,给数据库带来压力,严重导致打满mysql。
2 如果业务应用中读取数据库和写缓存的时间不好估算,那么,延迟双删中的等待时间就不好设置。
多补充一句:如果使用先更新数据库,再删除缓存的方案
如果业务层要求必须读取一致性的数据,那么我们就需要在更新数据库时,先在Redis缓存客户端暂存并发读请求,等数据库更新完、缓存值删除后,再读取数据,从而保证数据一致性。
23、Redis存储对象要么用string要么用hash,什么时候用string?什么时候用hash
在Redis中,可以使用string和hash来存储对象,它们各有优缺点,应根据具体场景进行选择。
当对象比较简单,只包含一个键值对时,可以使用string类型来存储对象。string类型的数据结构非常简单,存储效率高,适合存储简单的字符串、数字等数据类型。例如,可以使用string类型来存储用户的ID、用户名、年龄等信息。
当对象比较复杂,包含多个属性时,可以使用hash类型来存储对象。hash类型可以看作是一张哈希表,其中包含多个键值对,每个键值对表示对象的一个属性。使用hash类型可以更方便地存储和操作对象的各个属性,同时也可以节省存储空间。例如,可以使用hash类型来存储用户的详细信息,包括姓名、地址、电话等多个属性。
需要注意的是,当使用hash类型存储对象时,需要考虑到哈希表的扩容和缩容问题,因为哈希表的大小是固定的,当存储的键值对数量超过哈希表的负载因子时,Redis会自动扩容哈希表,从而导致一定的性能损耗和内存浪费。因此,在使用hash类型存储对象时,需要合理设置哈希表的初始大小和负载因子,以避免频繁扩容和浪费内存的情况发生。
24、你在项目中对Redis的使用,请不要说分布式锁
- 缓存:Redis可以作为缓存来提高系统的性能和响应速度。例如,可以将经常访问的数据存储在Redis中,避免每次请求都要从数据库中查询数据。
- 计数器:Redis可以用来实现计数器功能,例如统计网站的访问量、用户的登录次数等。通过INCR等命令可以实现原子性自增或自减操作。
- 消息队列:Redis可以用来实现简单的消息队列功能,例如将需要异步处理的任务放入Redis队列中,然后由后台线程或其他进程来消费队列中的任务。
- 分布式限流:Redis可以用来实现分布式限流功能,例如限制API的访问频率、防止爬虫等恶意行为。
- 排行榜:Redis可以用来实现排行榜功能,例如统计用户的积分、评论数等信息,然后根据这些信息来生成排行榜。
- 地理位置:Redis可以用来存储地理位置信息,例如根据经纬度查询附近的商家、朋友等。
以上只是一些简单的使用场景,Redis还有更多的用途,例如发布/订阅、持久化、事务等,可以根据项目需求来选择合适的使用方式。
25、美团面试官,直接打开App,请问我们美团附近的酒店你如何设计并落地,谈谈你的想法
- 地理位置服务:首先需要使用地理位置服务来获取用户的当前位置,可以使用GPS、WiFi、基站等多种方式来实现。获取到用户的位置后,可以使用地图API来显示周边的酒店信息。
- 数据存储:需要将酒店的信息存储到数据库中,例如酒店的名称、地址、评分、价格等信息。可以使用MySQL、Redis等数据库来存储数据,其中Redis可以作为缓存来提高查询效率。
- 搜索功能:可以使用全文检索引擎来实现搜索功能,例如Elasticsearch、Solr等。用户可以输入关键词来搜索酒店名称、地址等信息,搜索结果可以按照距离、价格、评分等多种方式进行排序。也可以使用Redis的GEO实现。
- 推荐功能:可以使用推荐算法来实现个性化推荐功能,例如根据用户的历史订单、浏览记录、评价等信息来推荐适合的酒店。可以使用协同过滤、基于内容的推荐、深度学习等算法来实现推荐功能。
- 营销功能:可以使用优惠券、积分、返现等营销手段来吸引用户下单。可以根据用户的购买习惯、地理位置等信息来精准投放优惠券等活动。
- 用户评论:用户可以对酒店进行评价和评论,可以使用机器学习等算法来自动分类、提取评论中的情感信息,从而帮助用户更好地选择酒店。
- 交易系统:最后需要建立完善的交易系统,包括订单生成、支付、退款、售后等功能。可以使用支付宝、微信支付等第三方支付平台来实现支付功能,可以使用客服系统来处理用户的售后问题。
以上是我对美团附近酒店的设计思路,针对不同的场景和需求,可以做出不同的调整和优化。
26、Redis的IO多路复用如何理解,为什么单线程还可以抗那么高的qps
IO多路复用简单说明
I/O 的读和写本身是堵塞的,比如当 socket 中有数据时,Redis 会通过调用先将数据从内核态空间拷贝到用户态空间,再交给 Redis 调用,而这个拷贝的过程就是阻塞的,当数据量越大时拷贝所需要的时间就越多,而这些操作都是基于单线程完成的。
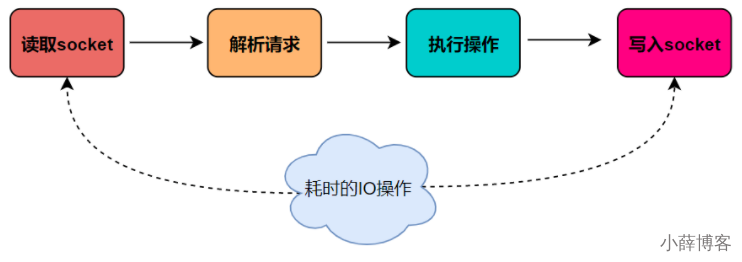
在 Redis 6.0 中新增了多线程的功能来提高 I/O 的读写性能,他的主要实现思路是将主线程的 IO 读写任务拆分给一组独立的线程去执行,这样就可以使多个 socket 的读写可以并行化了,采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),将最耗时的Socket的读取、请求解析、写入单独外包出去,剩下的命令执行仍然由主线程串行执行并和内存的数据交互。
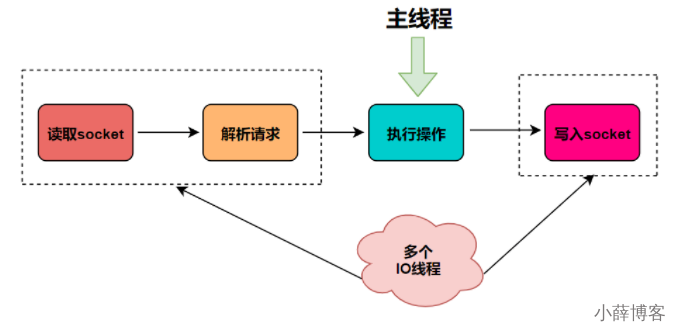
结合上图可知,网络IO操作就变成多线程化了,其他核心部分仍然是线程安全的,是个不错的折中办法。
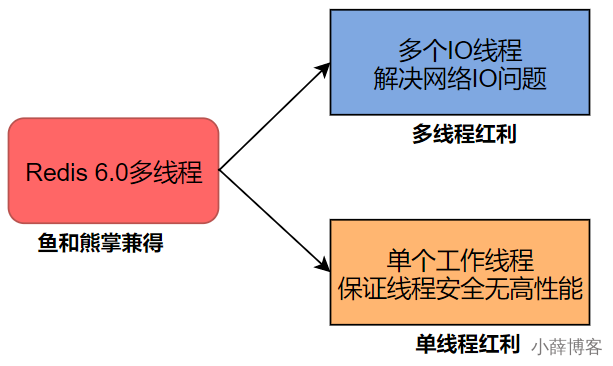
Redis 6.0 将网络数据读写、请求协议解析通过多个IO线程的来处理 ,对于真正的命令执行来说,仍然使用主线程操作,一举两得.
27、Redis的zset底层实现,说了压缩列表和跳表,问这样设计的优缺点
Redis中的zset是一种有序集合,它的底层实现采用了压缩列表和跳表的结构。
压缩列表是一种紧凑的线性结构,可以节省内存空间。在zset中,如果集合中的元素数量比较少,可以使用压缩列表来存储数据,因为压缩列表的结构比较简单,只需要存储元素的score和value即可。压缩列表的优点是占用内存小,但缺点是查询效率较低,因为需要遍历整个列表才能找到指定的元素。
跳表是一种高效的有序集合结构,可以快速地进行查找、插入和删除操作。在zset中,如果集合中的元素数量比较多,可以使用跳表来存储数据,因为跳表的查询效率比较高,可以在O(log n)的时间复杂度内查找元素。跳表的优点是查询效率高,但缺点是占用内存空间比较大。
综合来看,Redis中的zset底层实现采用了压缩列表和跳表的结构,可以在不同的场景下选择合适的数据结构来存储数据,从而达到节省内存空间和提高查询效率的目的。但是,这样的设计也存在一些缺点,例如在插入或删除元素时需要同时更新压缩列表和跳表,因此会增加一定的复杂度和开销。此外,压缩列表和跳表的结构比较复杂,需要占用一定的计算资源来维护和更新,因此可能会影响系统的性能和稳定性。
28、Redis的跳表说一下,解决了什么问题,时间复杂度和空间复杂度如何
Redis中的跳表(Skip List)是一种基于链表的数据结构,可以快速地进行查找、插入和删除操作,常用于实现有序集合和索引等功能。跳表的设计思想是通过增加多级索引来加速查找操作,从而达到快速查询的目的。
跳表的主要优势是通过平衡时间和空间复杂度来实现高效的查找操作,避免了传统的平衡二叉树需要维护平衡的复杂度和开销。跳表在插入、删除元素时,只需要更新相邻节点的索引,而不需要重新平衡整棵树,从而提高了操作的效率。因此,跳表的时间复杂度为O(log n),空间复杂度为O(n)。
跳表中包含多级索引,每一级索引都是一个有序的链表,索引节点的值比下一级索引节点的值大。跳表的最底层索引包含了所有的数据节点,因此可以通过最底层的索引进行查找。
在插入或删除元素时,需要在跳表中找到相应的位置,并更新相邻节点的索引。因为每一级索引的节点数是按照一定概率随机生成的,因此跳表的高度是随机的,但平均高度为O(log n)。
总之,跳表是一种高效的数据结构,可以在查找、插入和删除元素时达到O(log n)的时间复杂度,同时空间复杂度为O(n),适合用于实现有序集合和索引等功能。
29、IO多路复用select和epllo了解?
IO多路复用是指在单个线程内同时监视多个文件描述符,从而实现对I/O操作的异步处理。其中,select和epoll是两种常用的IO多路复用机制。
select是Unix系统中最古老的IO多路复用机制,它可以同时监视多个文件描述符,一旦某个文件描述符就绪,就会通知应用程序进行处理。select的缺点是它采用轮询的方式来监视文件描述符,当文件描述符的数量较多时,会导致系统开销较大,因此在高并发场景下效率不高。
epoll是Linux系统中较新的IO多路复用机制,它采用事件驱动的方式来监视文件描述符,并且可以支持较大的并发连接数,因此在高并发场景下效率更高。epoll的优点是它支持边缘触发和水平触发两种模式,可以更加精细地控制事件通知,从而提高了系统的性能和稳定性。
总之,select和epoll都是常用的IO多路复用机制,它们能够实现对多个文件描述符的异步处理和高效监视,但是epoll在高并发场景下的效率更高,因此在实际开发中应该根据具体情况选择合适的IO多路复用机制。
31、一个字符串类型的值能存储最大容量是多少?
Redis一个字符串类型的值最大能存储512MB的数据。这是由于Redis使用了一个名为sds(simple dynamic string)的数据结构来存储字符串,其最大长度为2^32-1字节,即4GB,但是Redis规定单个字符串对象的最大长度为512MB,这是为了确保Redis的性能和稳定性,在数据存储和传输过程中不会出现过度消耗内存、影响系统性能的情况。
32、Redis 的持久化机制是什么?各自的优缺点?
Redis 提供了不同级别的持久化方式:
- RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储.
- AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大.
- 如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式.
- 你也可以同时开启两种持久化方式, 在这种情况下, 当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整.
RDB
优点
- RDB是一个非常紧凑的文件,它保存了某个时间点得数据集,非常适用于数据集的备份,比如你可以在每个小时报保存一下过去24小时内的数据,同时每天保存过去30天的数据,这样即使出了问题你也可以根据需求恢复到不同版本的数据集.
- RDB是一个紧凑的单一文件,很方便传送到另一个远端数据中心或者亚马逊的S3(可能加密),非常适用于灾难恢复.
- RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能.
- 与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些.
缺点
- 如果你希望在redis意外停止工作(例如电源中断)的情况下丢失的数据最少的话,那么RDB不适合你.虽然你可以配置不同的save时间点(例如每隔5分钟并且对数据集有100个写的操作),是Redis要完整的保存整个数据集是一个比较繁重的工作,你通常会每隔5分钟或者更久做一次完整的保存,万一在Redis意外宕机,你可能会丢失几分钟的数据.
- RDB 需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,fork的过程是非常耗时的,可能会导致Redis在一些毫秒级内不能响应客户端的请求.如果数据集巨大并且CPU性能不是很好的情况下,这种情况会持续1秒,AOF也需要fork,但是你可以调节重写日志文件的频率来提高数据集的耐久度.
AOF
优点
- 使用AOF 会让你的Redis更加耐久: 你可以使用不同的fsync策略:无fsync,每秒fsync,每次写的时候fsync.使用默认的每秒fsync策略,Redis的性能依然很好(fsync是由后台线程进行处理的,主线程会尽力处理客户端请求),一旦出现故障,你最多丢失1秒的数据.
- AOF文件是一个只进行追加的日志文件,所以不需要写入seek,即使由于某些原因(磁盘空间已满,写的过程中宕机等等)未执行完整的写入命令,你也也可使用redis-check-aof工具修复这些问题.
- Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
- AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
缺点
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。
32、Redis 集群最大节点个数是多少?为什么redis集群的最大槽数是16384个?
Redis集群并没有使用一致性hash而是引入了哈希槽的概念。Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。但为什么哈希槽的数量是16384(2^14)个呢?
CRC16算法产生的hash值有16bit,该算法可以产生2^16=65536个值。
换句话说值是分布在0~65535之间。那作者在做mod运算的时候,为什么不mod65536,而选择mod16384?
https://github.com/redis/redis/issues/2576

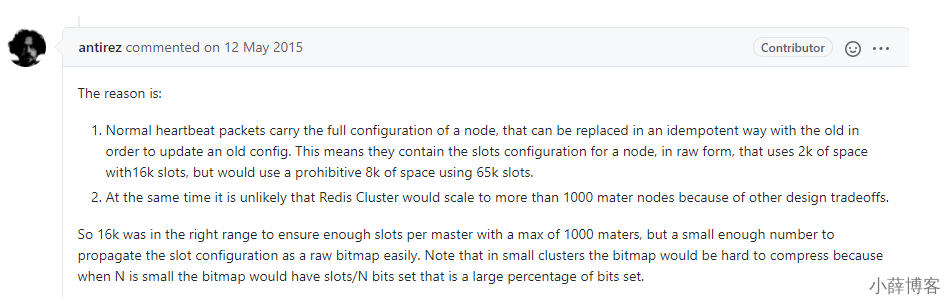
正常的心跳数据包带有节点的完整配置,可以用幂等方式用旧的节点替换旧节点,以便更新旧的配置。
这意味着它们包含原始节点的插槽配置,该节点使用2k的空间和16k的插槽,但是会使用8k的空间(使用65k的插槽)。
同时,由于其他设计折衷,Redis集群不太可能扩展到1000个以上的主节点。
因此16k处于正确的范围内,以确保每个主机具有足够的插槽,最多可容纳1000个矩阵,但数量足够少,可以轻松地将插槽配置作为原始位图传播。请注意,在小型群集中,位图将难以压缩,因为当N较小时,位图将设置的slot / N位占设置位的很大百分比。
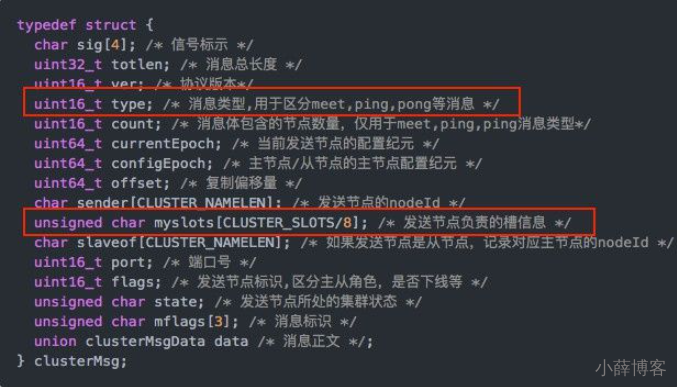
(1)如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大。
在消息头中最占空间的是myslots[CLUSTER_SLOTS/8]。 当槽位为65536时,这块的大小是: 65536÷8÷1024=8kb
因为每秒钟,redis节点需要发送一定数量的ping消息作为心跳包,如果槽位为65536,这个ping消息的消息头太大了,浪费带宽。
(2)redis的集群主节点数量基本不可能超过1000个。
集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者不建议redis cluster节点数量超过1000个。 那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了。没有必要拓展到65536个。
(3)槽位越小,节点少的情况下,压缩比高,容易传输
Redis主节点的配置信息中它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中会对bitmap进行压缩,但是如果bitmap的填充率slots / N很高的话(N表示节点数),bitmap的压缩率就很低。 如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很低。
33、MySQL 里有 2000w 数据,redis 中只存 20w 的数据,如何保证 redis 中的数据都是热点数据?
要保证Redis中存储的数据都是热点数据,可以考虑以下几种方式:
- 通过访问日志或监控系统等手段,对MySQL中的数据进行分析,找出访问频率较高的数据,然后将这部分数据同步到Redis中,保证Redis中的数据都是热点数据。
- 利用MySQL的binlog或者增量备份等功能,实现MySQL数据变化的实时同步到Redis中,这样就可以保证Redis中的数据都是最新的热点数据。
- 利用Redis的LRU算法,将访问频率较高的数据放在内存中,访问频率较低的数据缓存到磁盘中,这样可以保证Redis中存储的数据都是热点数据。同时,可以通过设置maxmemory和maxmemory-policy等参数来控制Redis中的缓存大小和数据淘汰策略,从而确保Redis中的数据都是热点数据。
综上所述,保证Redis中存储的数据都是热点数据,需要结合实际情况采取不同的策略,同时需要根据访问频率和数据量等因素来控制Redis中的缓存大小和数据淘汰策略,从而实现高效的数据存储和访问。
33、缓存雪崩、缓存击穿、缓存穿透
1、缓存雪崩
1、什么情况会发生雪崩
- redis主机挂了,Redis 全盘崩溃
- 比如缓存中有大量数据同时过期
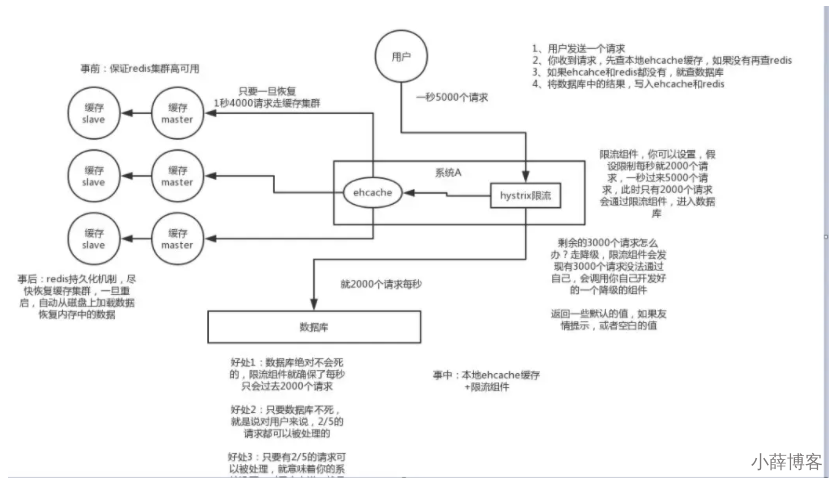
2、雪崩解决方案
- 构建多级缓存架构:nginx缓存 + redis缓存 +其他缓存(ehcache等)
- redis缓存集群实现高可用 (主从+哨兵,Redis Cluster)
- ehcache本地缓存 + Hystrix或者阿里sentinel限流&降级
- 开启Redis持久化机制aof/rdb,尽快恢复缓存集群
- 使用锁或队列
- 用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。不适用高并发情况
- 将缓存失效时间分散开
- 比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
2、缓存穿透
1、是什么
请求去查询一条记录,先redis后mysql发现都查询不到该条记录,但是请求每次都会打到数据库上面去,导致后台数据库压力暴增,这种现象我们称为缓存穿透,这个redis变成了一个摆设。。。。。。
key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会压到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
简单说就是本来无一物,既不在Redis缓存中,也不在数据库中
2、解决方案
方案1:空对象缓存或者缺省值

- 黑客或者恶意攻击
黑客会对你的系统进行攻击,拿一个不存在的id 去查询数据,会产生大量的请求到数据库去查询。可能会导致你的数据库由于压力过大而宕掉
id相同打你系统:第一次打到mysql,空对象缓存后第二次就返回null了,避免mysql被攻击,不用再到数据库中去走一圈了
id不同打你系统:由于存在空对象缓存和缓存回写(看自己业务不限死),redis中的无关紧要的key也会越写越多(记得设置redis过期时间)
方案2:Google布隆过滤器Guava解决缓存穿透
Guava 中布隆过滤器的实现算是比较权威的,所以实际项目中我们不需要手动实现一个布隆过滤器
Guava’s BloomFilter 源码剖析 https://github.com/google/guava/blob/master/guava/src/com/google/common/hash/BloomFilter.java
@Test
public void bloomFilter()
{
// 创建布隆过滤器对象
BloomFilter<Integer> filter = BloomFilter.create(Funnels.integerFunnel(), 100);
// 判断指定元素是否存在
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
// 将元素添加进布隆过滤器
filter.put(1);
filter.put(2);
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
}
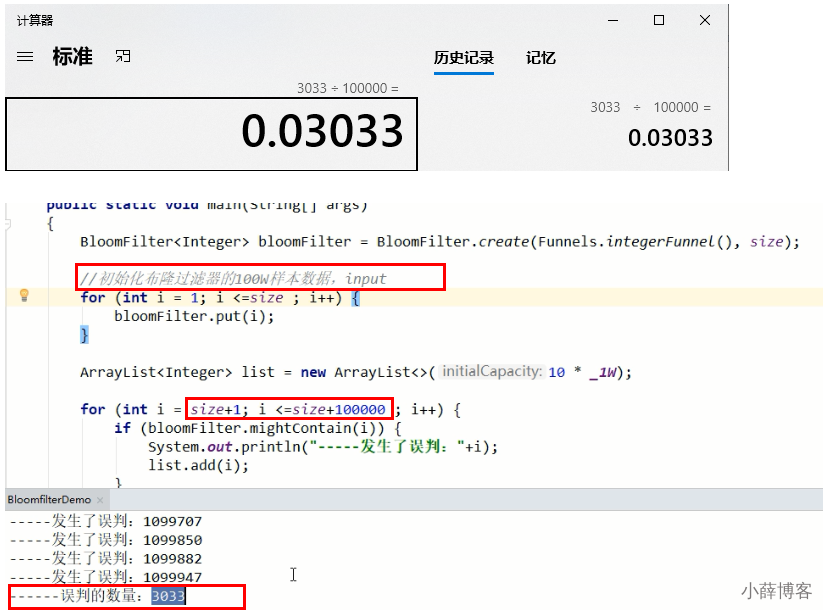
public static final int _1W = 10000;
//布隆过滤器里预计要插入多少数据
public static int size = 100 * _1W;
//误判率,它越小误判的个数也就越少(思考,是不是可以设置的无限小,没有误判岂不更好)
public static double fpp = 0.03;
// 构建布隆过滤器
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size,fpp);
public static void main(String[] args)
{
//1 先往布隆过滤器里面插入100万的样本数据
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
//故意取10万个不在过滤器里的值,看看有多少个会被认为在过滤器里
List<Integer> list = new ArrayList<>(10 * _1W);
for (int i = size+1; i < size + 100000; i++) {
if (bloomFilter.mightContain(i)) {
System.out.println(i+"\t"+"被误判了.");
list.add(i);
}
}
System.out.println("误判的数量:" + list.size());
}现在总共有10万数据是不存在的,误判了3033次,
原始样本:100W
不存在数据:101W---110W
方案3:Redis布隆过滤器解决缓存穿透
Guava缺点说明:
Guava 提供的布隆过滤器的实现还是很不错的 (想要详细了解的可以看一下它的源码实现),但是它有一个重大的缺陷就是只能单机使用 ,而现在互联网一般都是分布式的场景。
为了解决这个问题,我们就需要用到 Redis 中的布隆过滤器了
案例:白名单过滤器
- 白名单架构说明
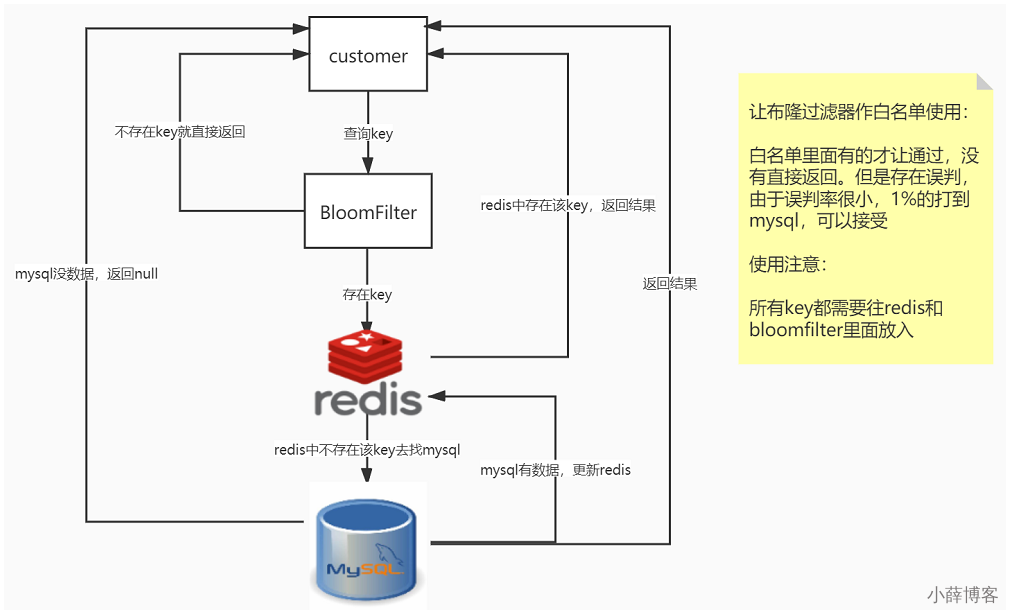
- 误判问题,但是概率小可以接受,不能从布隆过滤器删除
- 全部合法的key都需要放入过滤器+redis里面,不然数据就是返回null
public static final int _1W = 10000;
//布隆过滤器里预计要插入多少数据
public static int size = 100 * _1W;
//误判率,它越小误判的个数也就越少
public static double fpp = 0.03;
static RedissonClient redissonClient = null;
static RBloomFilter rBloomFilter = null;
static
{
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.111.147:6379").setDatabase(0);
//构造redisson
redissonClient = Redisson.create(config);
//通过redisson构造rBloomFilter
rBloomFilter = redissonClient.getBloomFilter("phoneListBloomFilter",new StringCodec());
rBloomFilter.tryInit(size,fpp);
// 1测试 布隆过滤器有+redis有
rBloomFilter.add("10086");
redissonClient.getBucket("10086",new StringCodec()).set("chinamobile10086");
// 2测试 布隆过滤器有+redis无
//rBloomFilter.add("10087");
//3 测试 ,都没有
}
public static void main(String[] args)
{
String phoneListById = getPhoneListById("10087");
System.out.println("------查询出来的结果: "+phoneListById);
//暂停几秒钟线程
try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }
redissonClient.shutdown();
}
private static String getPhoneListById(String IDNumber)
{
String result = null;
if (IDNumber == null) {
return null;
}
//1 先去布隆过滤器里面查询
if (rBloomFilter.contains(IDNumber)) {
//2 布隆过滤器里有,再去redis里面查询
RBucket<String> rBucket = redissonClient.getBucket(IDNumber, new StringCodec());
result = rBucket.get();
if(result != null)
{
return "i come from redis: "+result;
}else{
result = getPhoneListByMySQL(IDNumber);
if (result == null) {
return null;
}
// 重新将数据更新回redis
redissonClient.getBucket(IDNumber,new StringCodec()).set(result);
}
return "i come from mysql: "+result;
}
return result;
}
private static String getPhoneListByMySQL(String IDNumber)
{
return "chinamobile"+IDNumber;
}
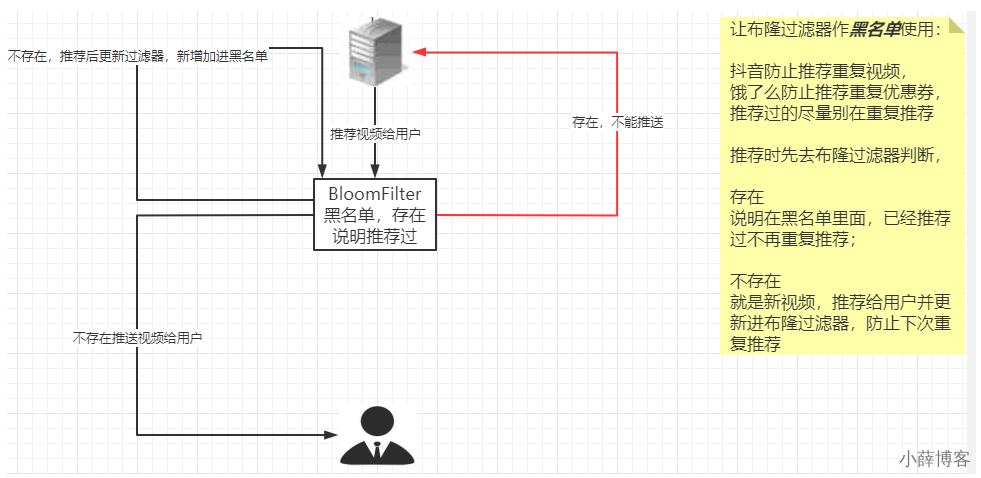
黑名单使用:
3、安装
1、采用docker安装RedisBloom,推荐
Redis 在 4.0 之后有了插件功能(Module),可以使用外部的扩展功能,
可以使用 RedisBloom 作为 Redis 布隆过滤器插件。
docker run -p 6379:6379 --name=redis6379bloom -d redislabs/rebloom
docker exec -it redis6379bloom /bin/bash redis-cli
bf.reserve filter 0.01 100
bf.add filter v11
bf.exists filter v11
bf.exists filter v12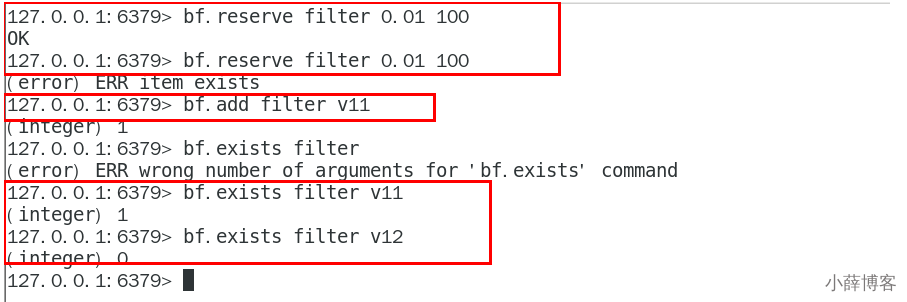
2、编译安装
# 下载 编译 安装Rebloom插件
wget https://github.com/RedisLabsModules/rebloom/archive/v2.2.2.tar.gz
# 解压
tar -zxvf v2.2.2.tar.gz
cd RedisBloom-2.2.2
# 若是第一次使用 需要安装gcc++环境
make
# redis服启动添加对应参数 这样写还是挺麻烦的
# rebloom_module="/usr/local/rebloom/rebloom.so"
# daemon --user ${REDIS_USER-redis} "$exec $REDIS_CONFIG --loadmodule # $rebloom_module --daemonize yes --pidfile $pidfile"
# 记录当前位置
pwd
# 进入reids目录 配置在redis.conf中 更加方便
vim redis.conf
# :/loadmodule redisbloom.so是刚才具体的pwd位置 cv一下
loadmodule /xxx/redis/redis-5.0.8/RedisBloom-2.2.2/redisbloom.so
# 保存退出
wq
# 重新启动redis-server 我是在redis中 操作的 若不在请写出具体位置 不然会报错
redis-server redis.conf
# 连接容器中的 redis 服务 若是无密码 redis-cli即可
redis-cli -a 密码
# 进入可以使用BF.ADD命令算成功3、缓存击穿
1、是什么
大量的请求同时查询一个 key 时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去
简单说就是热点key突然失效了,暴打mysql
危害:会造成某一时刻数据库请求量过大,压力剧增。
2、解决方案
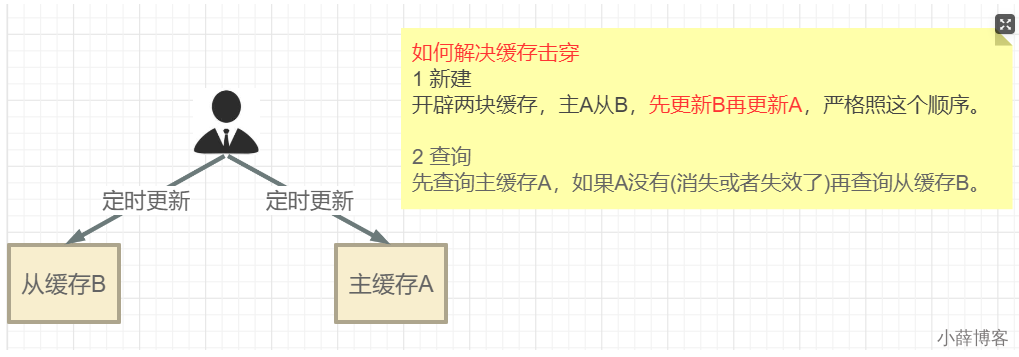
- 缓存击穿 - 热点key失效 - 互斥更新、随机退避、差异失效时间
- 对于访问频繁的热点key,干脆就不设置过期时间
- 互斥独占锁防止击穿
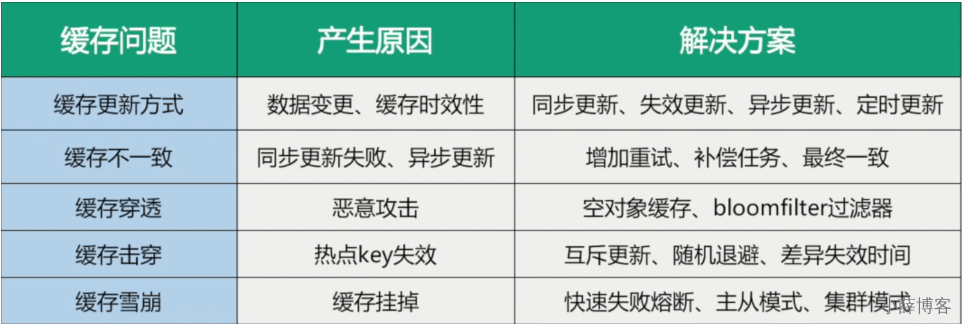
4、实际案例
高并发的淘宝聚划算案例落地


@Autowired
private RedisTemplate redisTemplate;
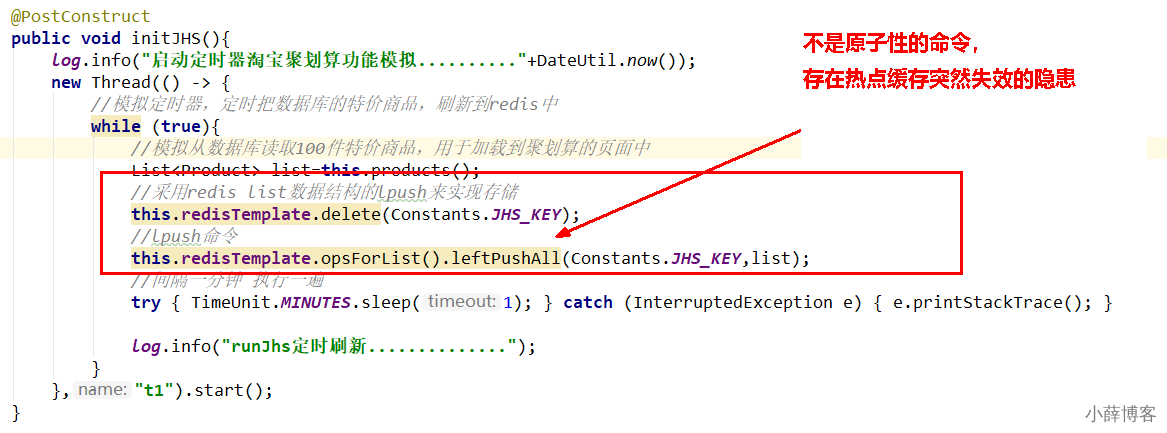
@PostConstruct
public void initJHS(){
log.info("启动定时器淘宝聚划算功能模拟.........."+DateUtil.now());
new Thread(() -> {
//模拟定时器,定时把数据库的特价商品,刷新到redis中
while (true){
//模拟从数据库读取100件特价商品,用于加载到聚划算的页面中
List<Product> list=this.products();
//采用redis list数据结构的lpush来实现存储
this.redisTemplate.delete(Constants.JHS_KEY);
//lpush命令
this.redisTemplate.opsForList().leftPushAll(Constants.JHS_KEY,list);
//间隔一分钟 执行一遍
try { TimeUnit.MINUTES.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }
log.info("runJhs定时刷新..............");
}
},"t1").start();
}
/**
* 模拟从数据库读取100件特价商品,用于加载到聚划算的页面中
*/
public List<Product> products() {
List<Product> list=new ArrayList<>();
for (int i = 1; i <=20; i++) {
Random rand = new Random();
int id= rand.nextInt(10000);
Product obj=new Product((long) id,"product"+i,i,"detail");
list.add(obj);
}
return list;
}
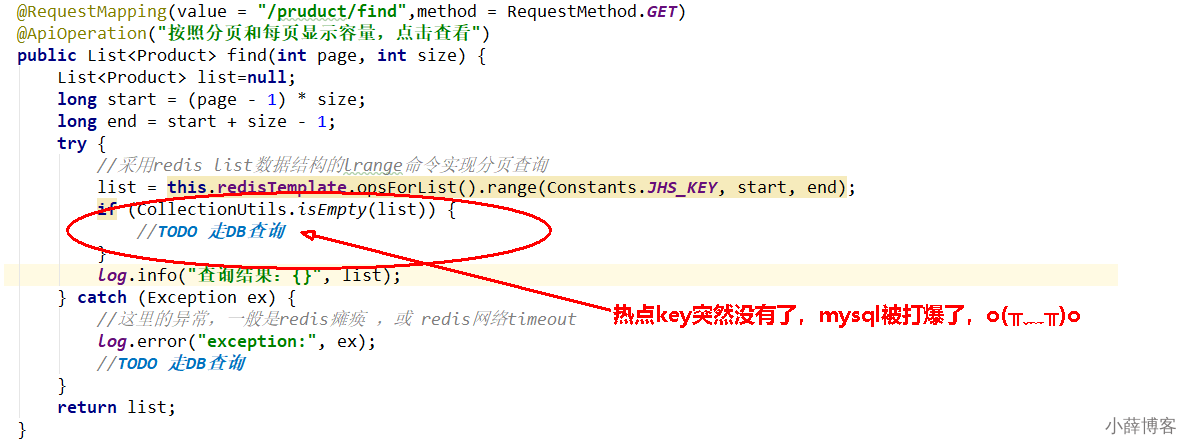
@Autowired
private RedisTemplate redisTemplate;
/**
* 分页查询:在高并发的情况下,只能走redis查询,走db的话必定会把db打垮
* http://localhost:5555/swagger-ui.html#/jhs-product-controller/findUsingGET
*/
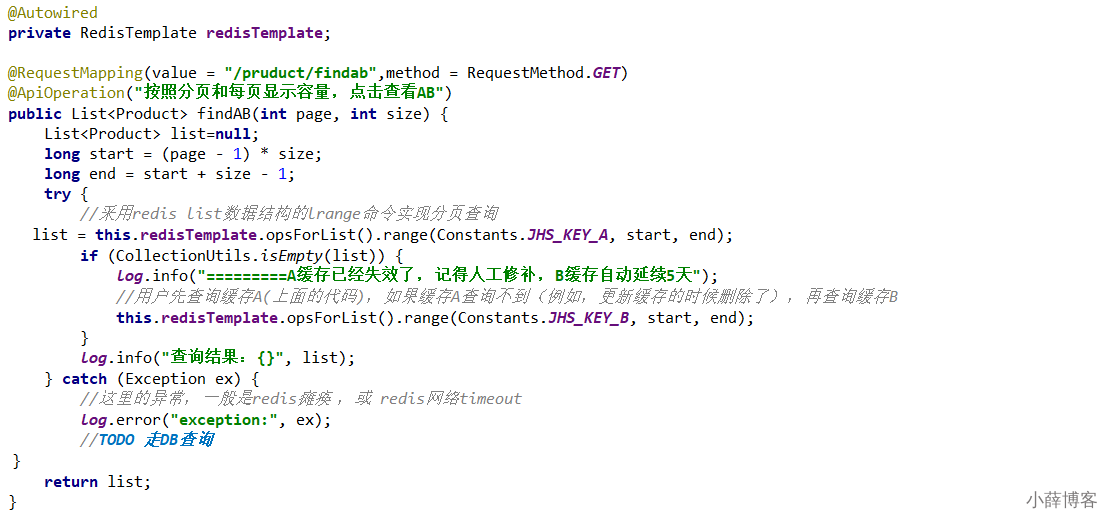
@RequestMapping(value = "/pruduct/find",method = RequestMethod.GET)
@ApiOperation("按照分页和每页显示容量,点击查看")
public List<Product> find(int page, int size) {
List<Product> list=null;
long start = (page - 1) * size;
long end = start + size - 1;
try {
//采用redis list数据结构的lrange命令实现分页查询
list = this.redisTemplate.opsForList().range(Constants.JHS_KEY, start, end);
if (CollectionUtils.isEmpty(list)) {
//TODO 走DB查询
}
log.info("查询结果:{}", list);
} catch (Exception ex) {
//这里的异常,一般是redis瘫痪 ,或 redis网络timeout
log.error("exception:", ex);
//TODO 走DB查询
}
return list;
}

34、redis的key存储多少数据可以称为大key
在Redis中,大key是指存储的数据量非常大的key,这会导致Redis在进行内存回收或数据持久化时,占用较多的内存或磁盘资源,从而影响Redis的性能和稳定性。虽然没有明确的标准来定义大key,但是一般认为,如果一个key存储的数据量超过10KB,就可以称之为大key。
需要注意的是,大key不仅会影响Redis的性能和稳定性,还会导致Redis集群中的数据分布不均,从而影响集群的负载均衡和可用性。因此,在使用Redis时,应该避免存储过大的数据量到单个key中,尽量采用拆分、分片等方式来分散数据,保证Redis的高效和稳定。
阿里的规范:https://developer.aliyun.com/article/531067
35、知道 redis 的持久化吗?底层如何实现的?有什么优点缺点?
RDB(Redis DataBase:在不同的时间点将 redis 的数据生成的快照同步到磁盘等介质上):内存到硬盘的快照,定期更新。缺点:耗时,耗性能(fork+io 操作),易丢失数据。
AOF(Append Only File:将 redis 所执行过的所有指令都记录下来,在下次 redis 重启时,只需要执行指令就可以了):写日志。缺点:体积大,恢复速度慢
bgsave 做镜像全量持久化,aof 做增量持久化。因为 bgsave 会消耗比较长的时间,不够实时,在停机的时候会导致大量的数据丢失,需要 aof 来配合,在 redis 实例重启时,优先使用 aof 来恢复内存的状态,如果没有 aof 日志,就会使用 rdb 文件来恢复。Redis 会定期做aof 重写,压缩 aof 文件日志大小。Redis4.0 之后有了混合持久化的功能,将 bgsave 的全量和 aof 的增量做了融合处理,这样既保证了恢复的效率又兼顾了数据的安全性。bgsave 的原理,fork 和 cow, fork 是指 redis 通过创建子进程来进行 bgsave 操作,cow 指的是 copy onwrite,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
36、大量数据写入redis,如何快速处理
Redis是一个内存数据库,写入速度非常快,可以支持每秒数十万次的写入操作。以下是一些在大量数据写入Redis时可以使用的技巧和优化:
1.使用pipeline批量写入:Redis支持通过pipeline方式进行批量写入,将多个命令打包到一起发送可以减少网络延迟和CPU消耗,从而提高写入性能。
2.使用Redis集群: Redis集群可以将数据分散到不同的节点上,从而提高写入性能和容量。同时,集群可以自动重定向请求到正确的分片上,提高可用性和负载均衡。
3.使用Redis事务:Redis事务可以将多个命令打包成原子性的操作,从而避免并发写入冲突和数据异常。
4.使用Redis持久化:Redis可以通过持久化方式,将内存中的数据异步或者同步地保存到磁盘上,保证数据的可靠性和持久性。
5.合理设置Redis参数:Redis有很多配置参数可以根据实际情况进行调整,例如最大内存限制、并发连接数、超时时间等等。
6.使用Redis缓存:如果写入操作不是那么紧急,可以考虑使用Redis做缓存,在缓存中进行写入操作,然后再批量更新到数据库中。
7.避免过期键:Redis中的过期键会占用内存,当过期键过多时可能会影响性能,应该根据实际情况合理设置过期时间或者使用惰性删除方式。
8.使用Redis Lua脚本:可以将多个操作打包到Lua脚本中运行,从而减少网络开销和命令调用次数。
总之,在处理大量数据写入Redis时,需要结合具体场景进行优化和调整,以提高性能和可靠性。